 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAging Memories Generate More Fluent Dialogue Responses with Memory Networks
Paper and Code
Nov 19, 2019

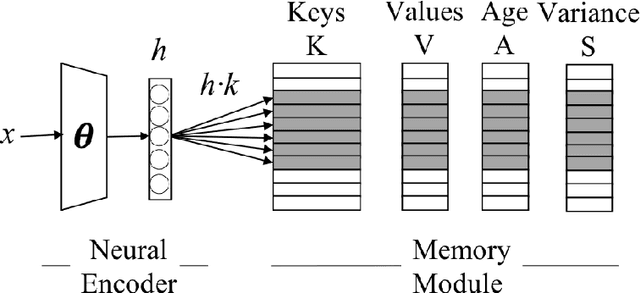
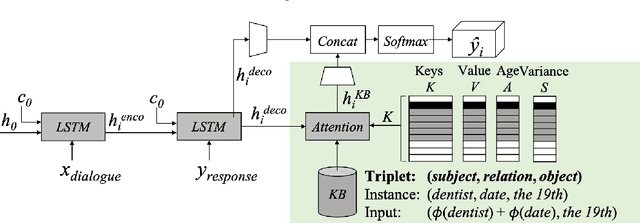
The integration of a Knowledge Base (KB) into a neural dialogue agent is one of the key challenges in Conversational AI. Memory networks has proven to be effective to encode KB information into an external memory to thus generate more fluent and informed responses. Unfortunately, such memory becomes full of latent representations during training, so the most common strategy is to overwrite old memory entries randomly. In this paper, we question this approach and provide experimental evidence showing that conventional memory networks generate many redundant latent vectors resulting in overfitting and the need for larger memories. We introduce memory dropout as an automatic technique that encourages diversity in the latent space by 1) Aging redundant memories to increase their probability of being overwritten during training 2) Sampling new memories that summarize the knowledge acquired by redundant memories. This technique allows us to incorporate Knowledge Bases to achieve state-of-the-art dialogue generation in the Stanford Multi-Turn Dialogue dataset. Considering the same architecture, its use provides an improvement of +2.2 BLEU points for the automatic generation of responses and an increase of +8.1% in the recognition of named entities.