 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of High-dimensional Autoregressive Generalized Linear Models
Jun 24, 2017


Vector autoregressive models characterize a variety of time series in which linear combinations of current and past observations can be used to accurately predict future observations. For instance, each element of an observation vector could correspond to a different node in a network, and the parameters of an autoregressive model would correspond to the impact of the network structure on the time series evolution. Often these models are used successfully in practice to learn the structure of social, epidemiological, financial, or biological neural networks. However, little is known about statistical guarantees on estimates of such models in non-Gaussian settings. This paper addresses the inference of the autoregressive parameters and associated network structure within a generalized linear model framework that includes Poisson and Bernoulli autoregressive processes. At the heart of this analysis is a sparsity-regularized maximum likelihood estimator. While sparsity-regularization is well-studied in the statistics and machine learning communities, those analysis methods cannot be applied to autoregressive generalized linear models because of the correlations and potential heteroscedasticity inherent in the observations. Sample complexity bounds are derived using a combination of martingale concentration inequalities and modern empirical process techniques for dependent random variables. These bounds, which are supported by several simulation studies, characterize the impact of various network parameters on estimator performance.
Tracking Dynamic Point Processes on Networks
Jul 01, 2016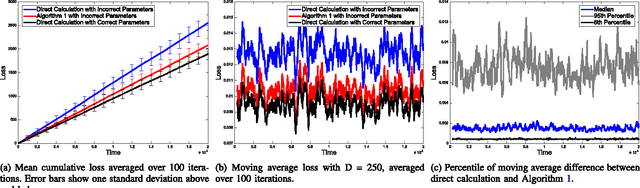
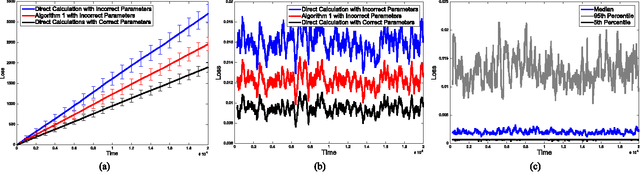
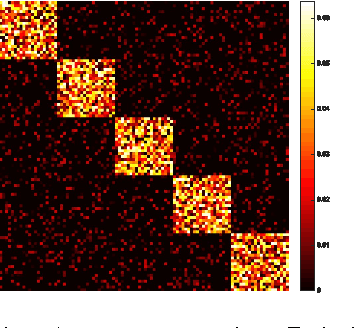
Cascading chains of events are a salient feature of many real-world social, biological, and financial networks. In social networks, social reciprocity accounts for retaliations in gang interactions, proxy wars in nation-state conflicts, or Internet memes shared via social media. Neuron spikes stimulate or inhibit spike activity in other neurons. Stock market shocks can trigger a contagion of volatility throughout a financial network. In these and other examples, only individual events associated with network nodes are observed, usually without knowledge of the underlying dynamic relationships between nodes. This paper addresses the challenge of tracking how events within such networks stimulate or influence future events. The proposed approach is an online learning framework well-suited to streaming data, using a multivariate Hawkes point process model to encapsulate autoregressive features of observed events within the social network. Recent work on online learning in dynamic environments is leveraged not only to exploit the dynamics within the underlying network, but also to track the network structure as it evolves. Regret bounds and experimental results demonstrate that the proposed method performs nearly as well as an oracle or batch algorithm.
Online Optimization in Dynamic Environments
Jan 19, 2016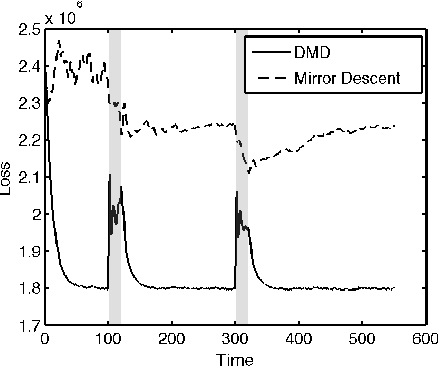
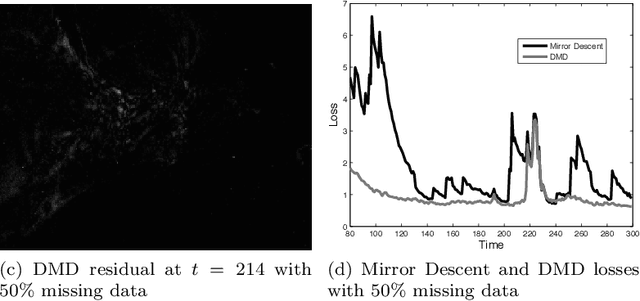

High-velocity streams of high-dimensional data pose significant "big data" analysis challenges across a range of applications and settings. Online learning and online convex programming play a significant role in the rapid recovery of important or anomalous information from these large datastreams. While recent advances in online learning have led to novel and rapidly converging algorithms, these methods are unable to adapt to nonstationary environments arising in real-world problems. This paper describes a dynamic mirror descent framework which addresses this challenge, yielding low theoretical regret bounds and accurate, adaptive, and computationally efficient algorithms which are applicable to broad classes of problems. The methods are capable of learning and adapting to an underlying and possibly time-varying dynamical model. Empirical results in the context of dynamic texture analysis, solar flare detection, sequential compressed sensing of a dynamic scene, traffic surveillance,tracking self-exciting point processes and network behavior in the Enron email corpus support the core theoretical findings.
* arXiv admin note: text overlap with arXiv:1301.1254
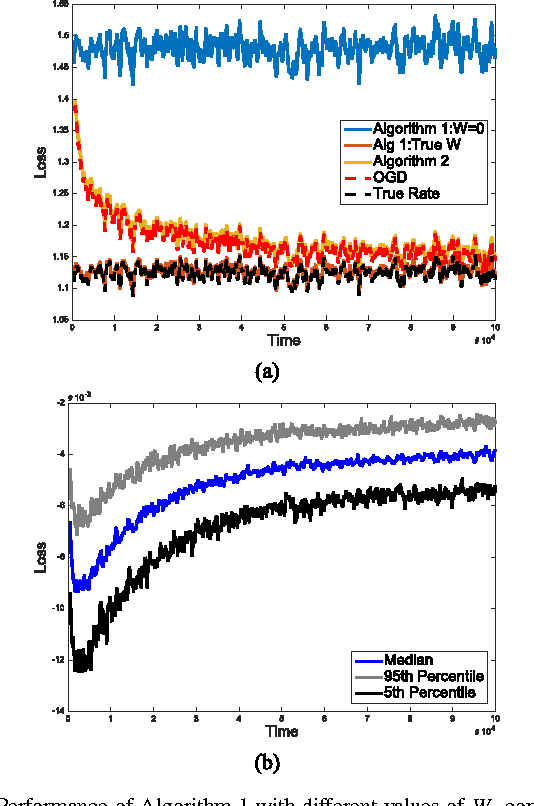
Dynamical Models and Tracking Regret in Online Convex Programming
Jan 07, 2013

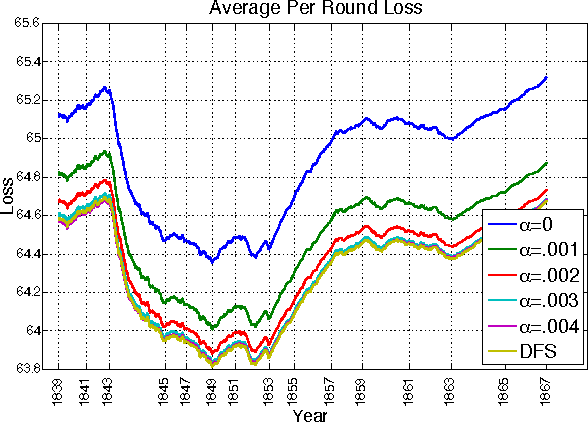
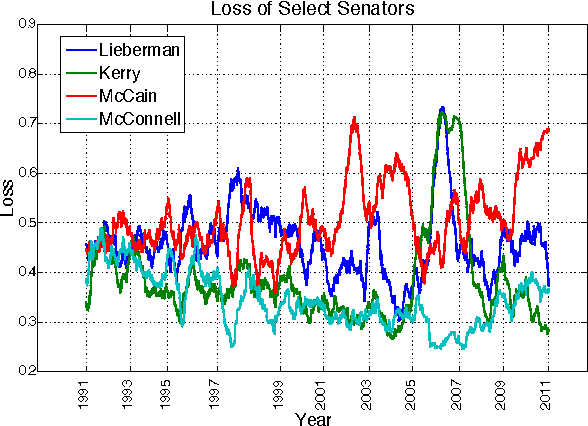
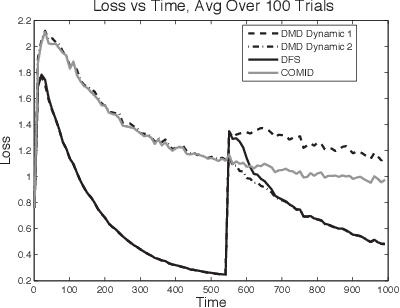
This paper describes a new online convex optimization method which incorporates a family of candidate dynamical models and establishes novel tracking regret bounds that scale with the comparator's deviation from the best dynamical model in this family. Previous online optimization methods are designed to have a total accumulated loss comparable to that of the best comparator sequence, and existing tracking or shifting regret bounds scale with the overall variation of the comparator sequence. In many practical scenarios, however, the environment is nonstationary and comparator sequences with small variation are quite weak, resulting in large losses. The proposed Dynamic Mirror Descent method, in contrast, can yield low regret relative to highly variable comparator sequences by both tracking the best dynamical model and forming predictions based on that model. This concept is demonstrated empirically in the context of sequential compressive observations of a dynamic scene and tracking a dynamic social network.