 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealing Double-Head: An Architecture for Online Calibration of Deep Neural Networks
Dec 27, 2022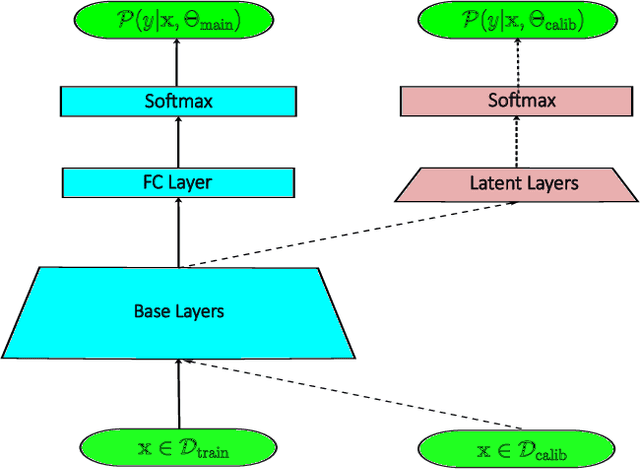
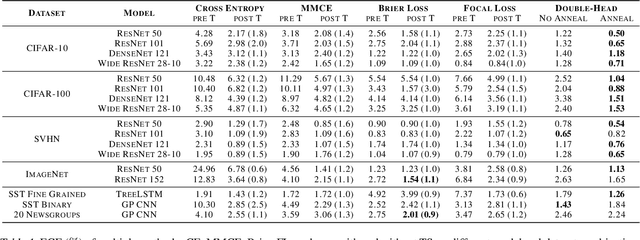


Model calibration, which is concerned with how frequently the model predicts correctly, not only plays a vital part in statistical model design, but also has substantial practical applications, such as optimal decision-making in the real world. However, it has been discovered that modern deep neural networks are generally poorly calibrated due to the overestimation (or underestimation) of predictive confidence, which is closely related to overfitting. In this paper, we propose Annealing Double-Head, a simple-to-implement but highly effective architecture for calibrating the DNN during training. To be precise, we construct an additional calibration head-a shallow neural network that typically has one latent layer-on top of the last latent layer in the normal model to map the logits to the aligned confidence. Furthermore, a simple Annealing technique that dynamically scales the logits by calibration head in training procedure is developed to improve its performance. Under both the in-distribution and distributional shift circumstances, we exhaustively evaluate our Annealing Double-Head architecture on multiple pairs of contemporary DNN architectures and vision and speech datasets. We demonstrate that our method achieves state-of-the-art model calibration performance without post-processing while simultaneously providing comparable predictive accuracy in comparison to other recently proposed calibration methods on a range of learning tasks.
Neural Tangent Kernel of Matrix Product States: Convergence and Applications
Nov 28, 2021
In this work, we study the Neural Tangent Kernel (NTK) of Matrix Product States (MPS) and the convergence of its NTK in the infinite bond dimensional limit. We prove that the NTK of MPS asymptotically converges to a constant matrix during the gradient descent (training) process (and also the initialization phase) as the bond dimensions of MPS go to infinity by the observation that the variation of the tensors in MPS asymptotically goes to zero during training in the infinite limit. By showing the positive-definiteness of the NTK of MPS, the convergence of MPS during the training in the function space (space of functions represented by MPS) is guaranteed without any extra assumptions of the data set. We then consider the settings of (supervised) Regression with Mean Square Error (RMSE) and (unsupervised) Born Machines (BM) and analyze their dynamics in the infinite bond dimensional limit. The ordinary differential equations (ODEs) which describe the dynamics of the responses of MPS in the RMSE and BM are derived and solved in the closed-form. For the Regression, we consider Mercer Kernels (Gaussian Kernels) and find that the evolution of the mean of the responses of MPS follows the largest eigenvalue of the NTK. Due to the orthogonality of the kernel functions in BM, the evolution of different modes (samples) decouples and the "characteristic time" of convergence in training is obtained.
Representation Theorem for Matrix Product States
Mar 15, 2021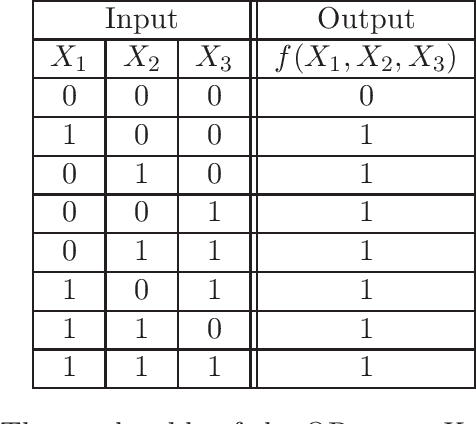
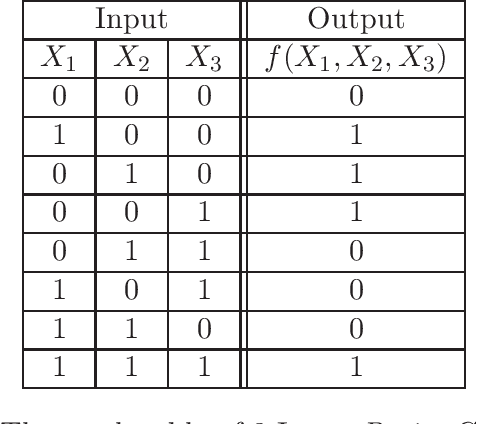
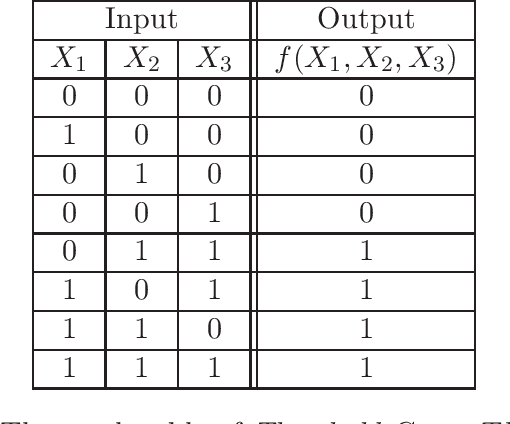
In this work, we investigate the universal representation capacity of the Matrix Product States (MPS) from the perspective of boolean functions and continuous functions. We show that MPS can accurately realize arbitrary boolean functions by providing a construction method of the corresponding MPS structure for an arbitrarily given boolean gate. Moreover, we prove that the function space of MPS with the scale-invariant sigmoidal activation is dense in the space of continuous functions defined on a compact subspace of the $n$-dimensional real coordinate space $\mathbb{R^{n}}$. We study the relation between MPS and neural networks and show that the MPS with a scale-invariant sigmoidal function is equivalent to a one-hidden-layer neural network equipped with a kernel function. We construct the equivalent neural networks for several specific MPS models and show that non-linear kernels such as the polynomial kernel which introduces the couplings between different components of the input into the model appear naturally in the equivalent neural networks. At last, we discuss the realization of the Gaussian Process (GP) with infinitely wide MPS by studying their equivalent neural networks.
Infinitely Wide Tensor Networks as Gaussian Process
Jan 07, 2021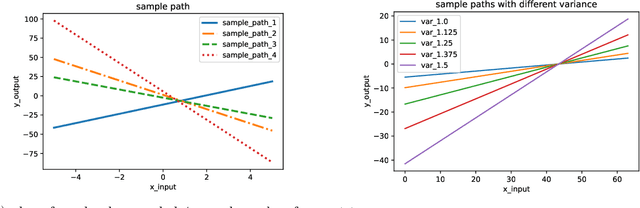

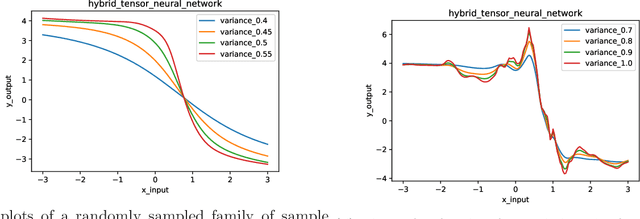
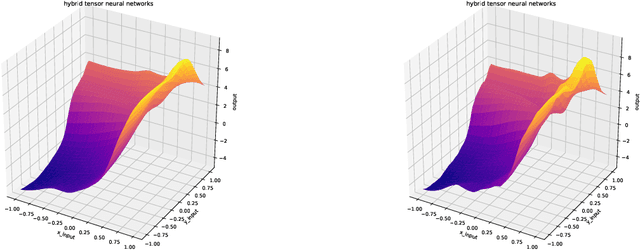
Gaussian Process is a non-parametric prior which can be understood as a distribution on the function space intuitively. It is known that by introducing appropriate prior to the weights of the neural networks, Gaussian Process can be obtained by taking the infinite-width limit of the Bayesian neural networks from a Bayesian perspective. In this paper, we explore the infinitely wide Tensor Networks and show the equivalence of the infinitely wide Tensor Networks and the Gaussian Process. We study the pure Tensor Network and another two extended Tensor Network structures: Neural Kernel Tensor Network and Tensor Network hidden layer Neural Network and prove that each one will converge to the Gaussian Process as the width of each model goes to infinity. (We note here that Gaussian Process can also be obtained by taking the infinite limit of at least one of the bond dimensions $\alpha_{i}$ in the product of tensor nodes, and the proofs can be done with the same ideas in the proofs of the infinite-width cases.) We calculate the mean function (mean vector) and the covariance function (covariance matrix) of the finite dimensional distribution of the induced Gaussian Process by the infinite-width tensor network with a general set-up. We study the properties of the covariance function and derive the approximation of the covariance function when the integral in the expectation operator is intractable. In the numerical experiments, we implement the Gaussian Process corresponding to the infinite limit tensor networks and plot the sample paths of these models. We study the hyperparameters and plot the sample path families in the induced Gaussian Process by varying the standard deviations of the prior distributions. As expected, the parameters in the prior distribution namely the hyper-parameters in the induced Gaussian Process controls the characteristic lengthscales of the Gaussian Process.
The Bayesian Method of Tensor Networks
Jan 01, 2021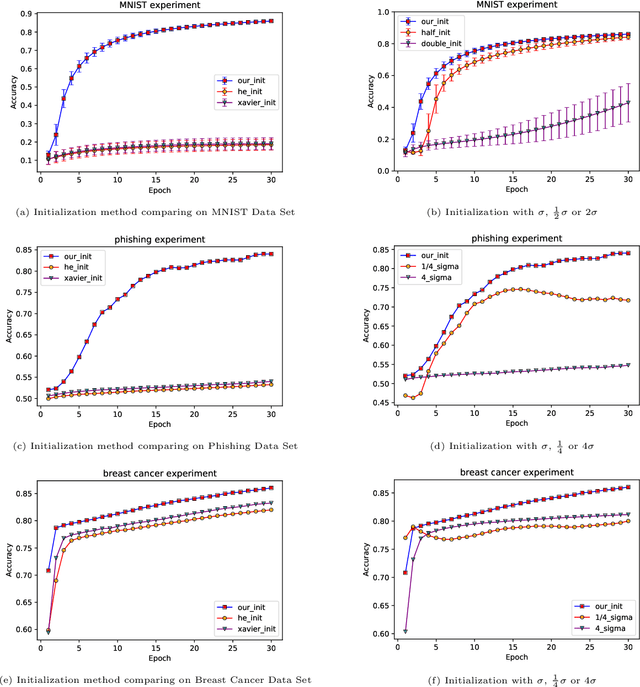
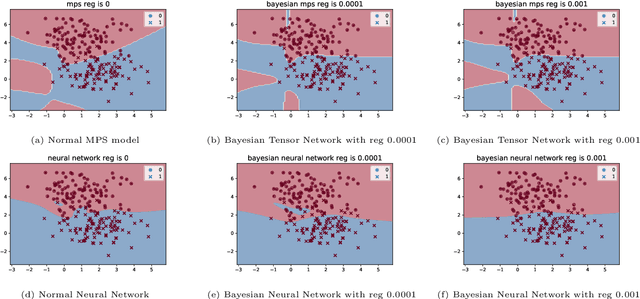
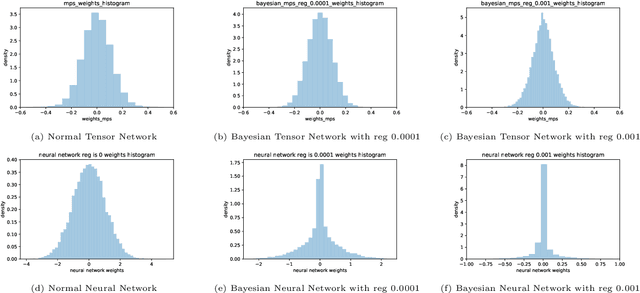

Bayesian learning is a powerful learning framework which combines the external information of the data (background information) with the internal information (training data) in a logically consistent way in inference and prediction. By Bayes rule, the external information (prior distribution) and the internal information (training data likelihood) are combined coherently, and the posterior distribution and the posterior predictive (marginal) distribution obtained by Bayes rule summarize the total information needed in the inference and prediction, respectively. In this paper, we study the Bayesian framework of the Tensor Network from two perspective. First, we introduce the prior distribution to the weights in the Tensor Network and predict the labels of the new observations by the posterior predictive (marginal) distribution. Since the intractability of the parameter integral in the normalization constant computation, we approximate the posterior predictive distribution by Laplace approximation and obtain the out-product approximation of the hessian matrix of the posterior distribution of the Tensor Network model. Second, to estimate the parameters of the stationary mode, we propose a stable initialization trick to accelerate the inference process by which the Tensor Network can converge to the stationary path more efficiently and stably with gradient descent method. We verify our work on the MNIST, Phishing Website and Breast Cancer data set. We study the Bayesian properties of the Bayesian Tensor Network by visualizing the parameters of the model and the decision boundaries in the two dimensional synthetic data set. For a application purpose, our work can reduce the overfitting and improve the performance of normal Tensor Network model.