 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinitely Wide Tensor Networks as Gaussian Process
Paper and Code
Jan 07, 2021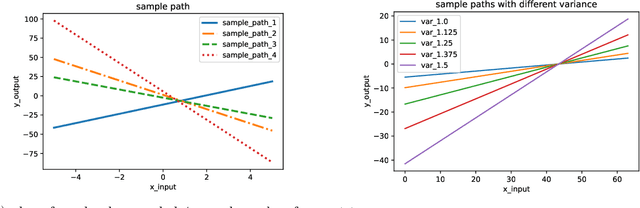

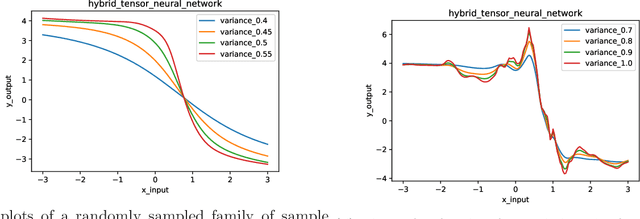
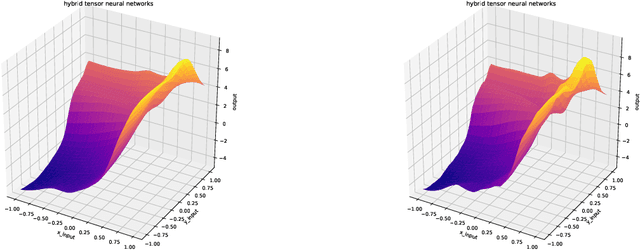
Gaussian Process is a non-parametric prior which can be understood as a distribution on the function space intuitively. It is known that by introducing appropriate prior to the weights of the neural networks, Gaussian Process can be obtained by taking the infinite-width limit of the Bayesian neural networks from a Bayesian perspective. In this paper, we explore the infinitely wide Tensor Networks and show the equivalence of the infinitely wide Tensor Networks and the Gaussian Process. We study the pure Tensor Network and another two extended Tensor Network structures: Neural Kernel Tensor Network and Tensor Network hidden layer Neural Network and prove that each one will converge to the Gaussian Process as the width of each model goes to infinity. (We note here that Gaussian Process can also be obtained by taking the infinite limit of at least one of the bond dimensions $\alpha_{i}$ in the product of tensor nodes, and the proofs can be done with the same ideas in the proofs of the infinite-width cases.) We calculate the mean function (mean vector) and the covariance function (covariance matrix) of the finite dimensional distribution of the induced Gaussian Process by the infinite-width tensor network with a general set-up. We study the properties of the covariance function and derive the approximation of the covariance function when the integral in the expectation operator is intractable. In the numerical experiments, we implement the Gaussian Process corresponding to the infinite limit tensor networks and plot the sample paths of these models. We study the hyperparameters and plot the sample path families in the induced Gaussian Process by varying the standard deviations of the prior distributions. As expected, the parameters in the prior distribution namely the hyper-parameters in the induced Gaussian Process controls the characteristic lengthscales of the Gaussian Process.