 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bayesian Method of Tensor Networks
Paper and Code
Jan 01, 2021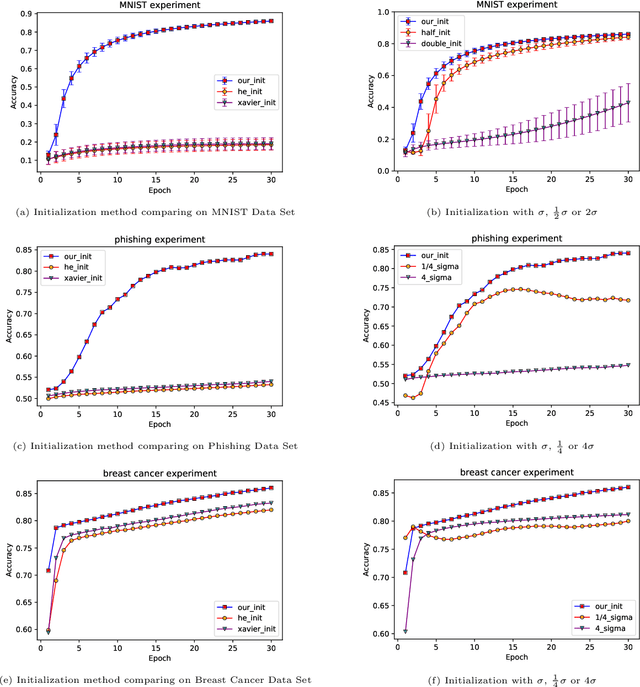
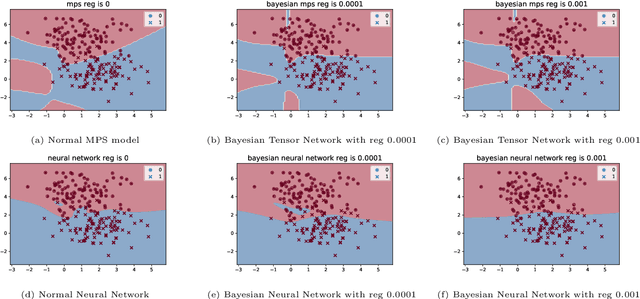
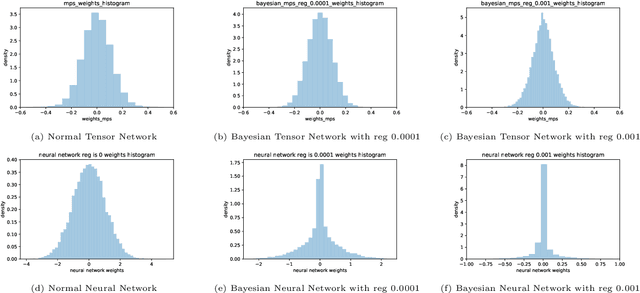

Bayesian learning is a powerful learning framework which combines the external information of the data (background information) with the internal information (training data) in a logically consistent way in inference and prediction. By Bayes rule, the external information (prior distribution) and the internal information (training data likelihood) are combined coherently, and the posterior distribution and the posterior predictive (marginal) distribution obtained by Bayes rule summarize the total information needed in the inference and prediction, respectively. In this paper, we study the Bayesian framework of the Tensor Network from two perspective. First, we introduce the prior distribution to the weights in the Tensor Network and predict the labels of the new observations by the posterior predictive (marginal) distribution. Since the intractability of the parameter integral in the normalization constant computation, we approximate the posterior predictive distribution by Laplace approximation and obtain the out-product approximation of the hessian matrix of the posterior distribution of the Tensor Network model. Second, to estimate the parameters of the stationary mode, we propose a stable initialization trick to accelerate the inference process by which the Tensor Network can converge to the stationary path more efficiently and stably with gradient descent method. We verify our work on the MNIST, Phishing Website and Breast Cancer data set. We study the Bayesian properties of the Bayesian Tensor Network by visualizing the parameters of the model and the decision boundaries in the two dimensional synthetic data set. For a application purpose, our work can reduce the overfitting and improve the performance of normal Tensor Network model.