 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Memorization in Video Diffusion Models
Oct 29, 2024

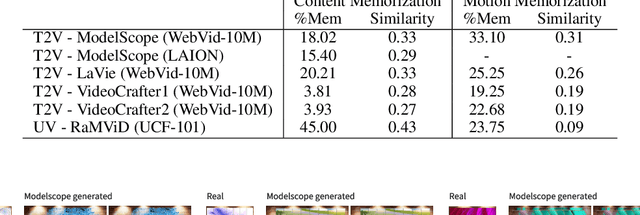

Diffusion models, widely used for image and video generation, face a significant limitation: the risk of memorizing and reproducing training data during inference, potentially generating unauthorized copyrighted content. While prior research has focused on image diffusion models (IDMs), video diffusion models (VDMs) remain underexplored. To address this gap, we first formally define the two types of memorization in VDMs (content memorization and motion memorization) in a practical way that focuses on privacy preservation and applies to all generation types. We then introduce new metrics specifically designed to separately assess content and motion memorization in VDMs. Additionally, we curate a dataset of text prompts that are most prone to triggering memorization when used as conditioning in VDMs. By leveraging these prompts, we generate diverse videos from various open-source VDMs, successfully extracting numerous training videos from each tested model. Through the application of our proposed metrics, we systematically analyze memorization across various pretrained VDMs, including text-conditional and unconditional models, on a variety of datasets. Our comprehensive study reveals that memorization is widespread across all tested VDMs, indicating that VDMs can also memorize image training data in addition to video datasets. Finally, we propose efficient and effective detection strategies for both content and motion memorization, offering a foundational approach for improving privacy in VDMs.