 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Based Sign Language Video Summarization using Curvature and Torsion
Jun 02, 2023An interesting problem in many video-based applications is the generation of short synopses by selecting the most informative frames, a procedure which is known as video summarization. For sign language videos the benefits of using the $t$-parameterized counterpart of the curvature of the 2-D signer's wrist trajectory to identify keyframes, have been recently reported in the literature. In this paper we extend these ideas by modeling the 3-D hand motion that is extracted from each frame of the video. To this end we propose a new informative function based on the $t$-parameterized curvature and torsion of the 3-D trajectory. The method to characterize video frames as keyframes depends on whether the motion occurs in 2-D or 3-D space. Specifically, in the case of 3-D motion we look for the maxima of the harmonic mean of the curvature and torsion of the target's trajectory; in the planar motion case we seek for the maxima of the trajectory's curvature. The proposed 3-D feature is experimentally evaluated in applications of sign language videos on (1) objective measures using ground-truth keyframe annotations, (2) human-based evaluation of understanding, and (3) gloss classification and the results obtained are promising.
Kernel-Based Training of Generative Networks
Nov 23, 2018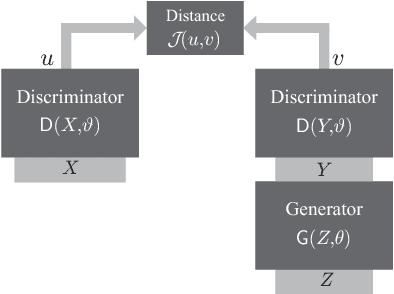

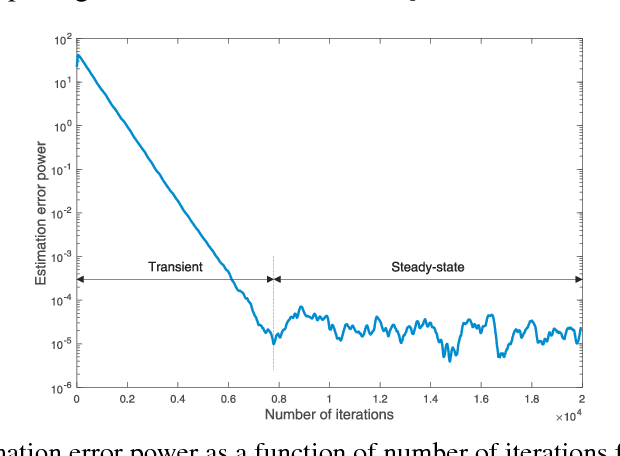
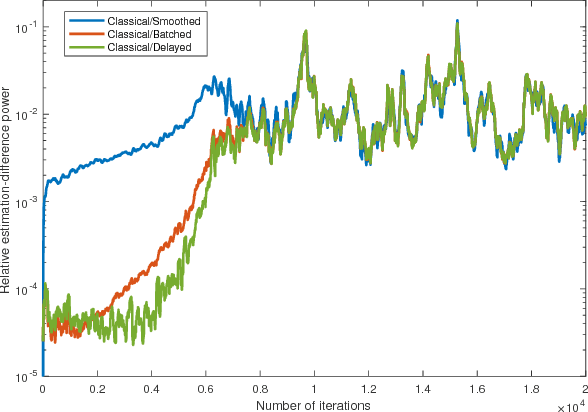
Generative adversarial networks (GANs) are designed with the help of min-max optimization problems that are solved with stochastic gradient-type algorithms which are known to be non-robust. In this work we revisit a non-adversarial method based on kernels which relies on a pure minimization problem and propose a simple stochastic gradient algorithm for the computation of its solution. Using simplified tools from Stochastic Approximation theory we demonstrate that batch versions of the algorithm or smoothing of the gradient do not improve convergence. These observations allow for the development of a training algorithm that enjoys reduced computational complexity and increased robustness while exhibiting similar synthesis characteristics as classical GANs.