 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising Simulation-Based Program Equilibria
Dec 19, 2024In Tennenholtz's program equilibrium, players of a game submit programs to play on their behalf. Each program receives the other programs' source code and outputs an action. This can model interactions involving AI agents, mutually transparent institutions, or commitments. Tennenholtz (2004) proves a folk theorem for program games, but the equilibria constructed are very brittle. We therefore consider simulation-based programs -- i.e., programs that work by running opponents' programs. These are relatively robust (in particular, two programs that act the same are treated the same) and are more practical than proof-based approaches. Oesterheld's (2019) $\epsilon$Grounded$\pi$Bot is such an approach. Unfortunately, it is not generally applicable to games of three or more players, and only allows for a limited range of equilibria in two player games. In this paper, we propose a generalisation to Oesterheld's (2019) $\epsilon$Grounded$\pi$Bot. We prove a folk theorem for our programs in a setting with access to a shared source of randomness. We then characterise their equilibria in a setting without shared randomness. Both with and without shared randomness, we achieve a much wider range of equilibria than Oesterheld's (2019) $\epsilon$Grounded$\pi$Bot. Finally, we explore the limits of simulation-based program equilibrium, showing that the Tennenholtz folk theorem cannot be attained by simulation-based programs without access to shared randomness.
A dataset of questions on decision-theoretic reasoning in Newcomb-like problems
Nov 21, 2024



We introduce a dataset of natural-language questions in the decision theory of so-called Newcomb-like problems. Newcomb-like problems include, for instance, decision problems in which an agent interacts with a similar other agent, and thus has to reason about the fact that the other agent will likely reason in similar ways. Evaluating LLM reasoning about Newcomb-like problems is important because interactions between foundation-model-based agents will often be Newcomb-like. Some ways of reasoning about Newcomb-like problems may allow for greater cooperation between models. Our dataset contains both capabilities questions (i.e., questions with a unique, uncontroversially correct answer) and attitude questions (i.e., questions about which decision theorists would disagree). We use our dataset for an investigation of decision-theoretical capabilities and expressed attitudes and their interplay in existing models (different models by OpenAI, Anthropic, Meta, GDM, Reka, etc.), as well as models under simple prompt-based interventions. We find, among other things, that attitudes vary significantly between existing models; that high capabilities are associated with attitudes more favorable toward so-called evidential decision theory; and that attitudes are consistent across different types of questions.
Can CDT rationalise the ex ante optimal policy via modified anthropics?
Nov 07, 2024
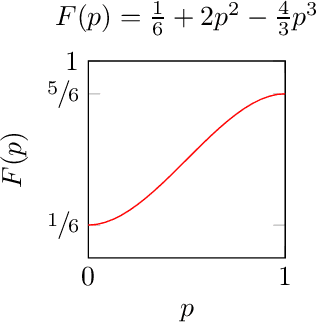
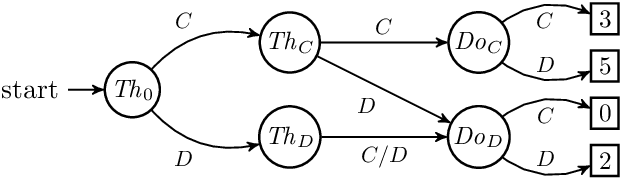
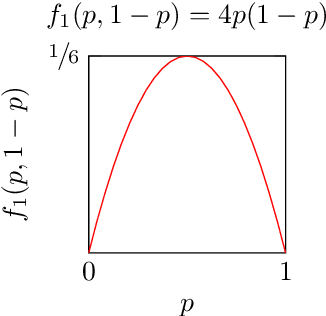
In Newcomb's problem, causal decision theory (CDT) recommends two-boxing and thus comes apart from evidential decision theory (EDT) and ex ante policy optimisation (which prescribe one-boxing). However, in Newcomb's problem, you should perhaps believe that with some probability you are in a simulation run by the predictor to determine whether to put a million dollars into the opaque box. If so, then causal decision theory might recommend one-boxing in order to cause the predictor to fill the opaque box. In this paper, we study generalisations of this approach. That is, we consider general Newcomblike problems and try to form reasonable self-locating beliefs under which CDT's recommendations align with an EDT-like notion of ex ante policy optimisation. We consider approaches in which we model the world as running simulations of the agent, and an approach not based on such models (which we call 'Generalised Generalised Thirding', or GGT). For each approach, we characterise the resulting CDT policies, and prove that under certain conditions, these include the ex ante optimal policies.
Incentivizing honest performative predictions with proper scoring rules
May 30, 2023Proper scoring rules incentivize experts to accurately report beliefs, assuming predictions cannot influence outcomes. We relax this assumption and investigate incentives when predictions are performative, i.e., when they can influence the outcome of the prediction, such as when making public predictions about the stock market. We say a prediction is a fixed point if it accurately reflects the expert's beliefs after that prediction has been made. We show that in this setting, reports maximizing expected score generally do not reflect an expert's beliefs, and we give bounds on the inaccuracy of such reports. We show that, for binary predictions, if the influence of the expert's prediction on outcomes is bounded, it is possible to define scoring rules under which optimal reports are arbitrarily close to fixed points. However, this is impossible for predictions over more than two outcomes. We also perform numerical simulations in a toy setting, showing that our bounds are tight in some situations and that prediction error is often substantial (greater than 5-10%). Lastly, we discuss alternative notions of optimality, including performative stability, and show that they incentivize reporting fixed points.