 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Scoring Rules: Zero-Sum Competition Avoids Performative Prediction
Dec 30, 2024In a decision-making scenario, a principal could use conditional predictions from an expert agent to inform their choice. However, this approach would introduce a fundamental conflict of interest. An agent optimizing for predictive accuracy is incentivized to manipulate their principal towards more predictable actions, which prevents that principal from being able to deterministically select their true preference. We demonstrate that this impossibility result can be overcome through the joint evaluation of multiple agents. When agents are made to engage in zero-sum competition, their incentive to influence the action taken is eliminated, and the principal can identify and take the action they most prefer. We further prove that this zero-sum setup is unique, efficiently implementable, and applicable under stochastic choice. Experiments in a toy environment demonstrate that training on a zero-sum objective significantly enhances both predictive accuracy and principal utility, and can eliminate previously learned manipulative behavior.
Incentivizing honest performative predictions with proper scoring rules
May 30, 2023Proper scoring rules incentivize experts to accurately report beliefs, assuming predictions cannot influence outcomes. We relax this assumption and investigate incentives when predictions are performative, i.e., when they can influence the outcome of the prediction, such as when making public predictions about the stock market. We say a prediction is a fixed point if it accurately reflects the expert's beliefs after that prediction has been made. We show that in this setting, reports maximizing expected score generally do not reflect an expert's beliefs, and we give bounds on the inaccuracy of such reports. We show that, for binary predictions, if the influence of the expert's prediction on outcomes is bounded, it is possible to define scoring rules under which optimal reports are arbitrarily close to fixed points. However, this is impossible for predictions over more than two outcomes. We also perform numerical simulations in a toy setting, showing that our bounds are tight in some situations and that prediction error is often substantial (greater than 5-10%). Lastly, we discuss alternative notions of optimality, including performative stability, and show that they incentivize reporting fixed points.
Conditioning Predictive Models: Risks and Strategies
Feb 06, 2023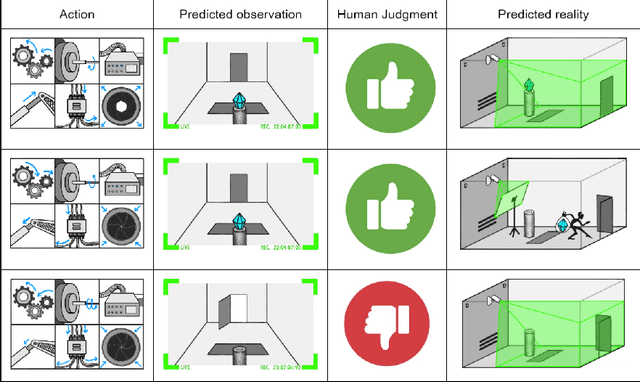
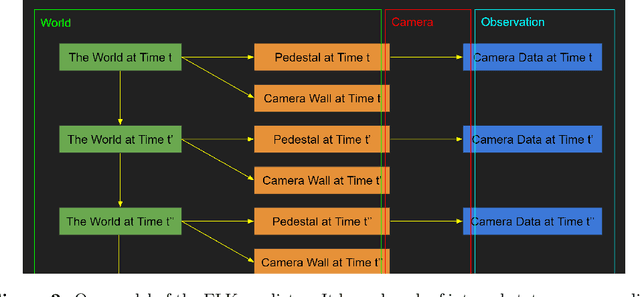
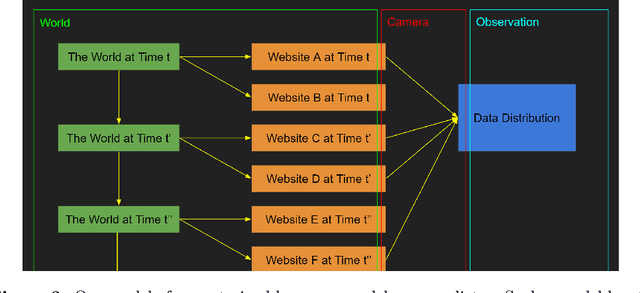
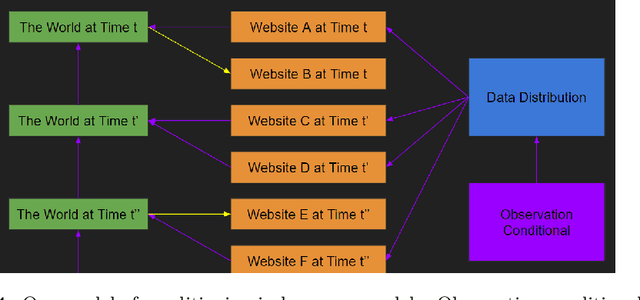
Our intention is to provide a definitive reference on what it would take to safely make use of generative/predictive models in the absence of a solution to the Eliciting Latent Knowledge problem. Furthermore, we believe that large language models can be understood as such predictive models of the world, and that such a conceptualization raises significant opportunities for their safe yet powerful use via carefully conditioning them to predict desirable outputs. Unfortunately, such approaches also raise a variety of potentially fatal safety problems, particularly surrounding situations where predictive models predict the output of other AI systems, potentially unbeknownst to us. There are numerous potential solutions to such problems, however, primarily via carefully conditioning models to predict the things we want (e.g. humans) rather than the things we don't (e.g. malign AIs). Furthermore, due to the simplicity of the prediction objective, we believe that predictive models present the easiest inner alignment problem that we are aware of. As a result, we think that conditioning approaches for predictive models represent the safest known way of eliciting human-level and slightly superhuman capabilities from large language models and other similar future models.