 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Predictive Models: Risks and Strategies
Feb 06, 2023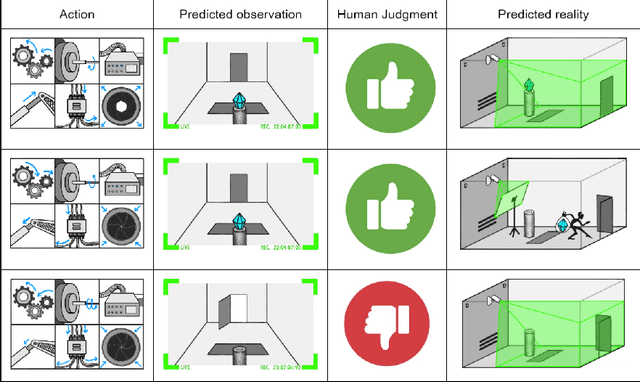
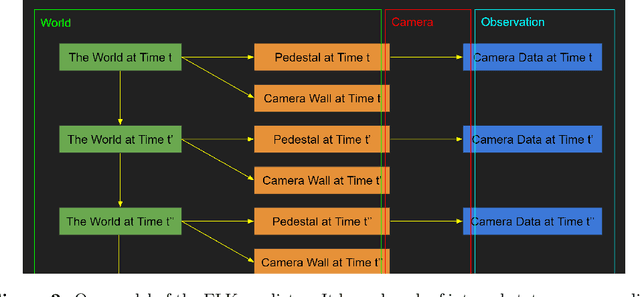
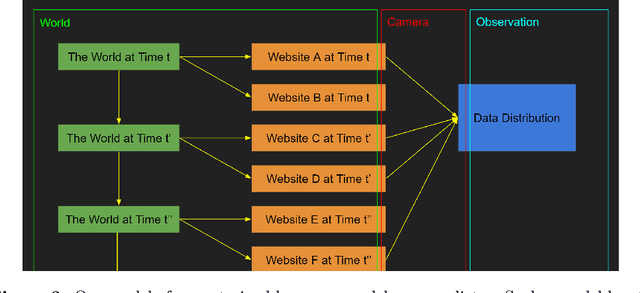
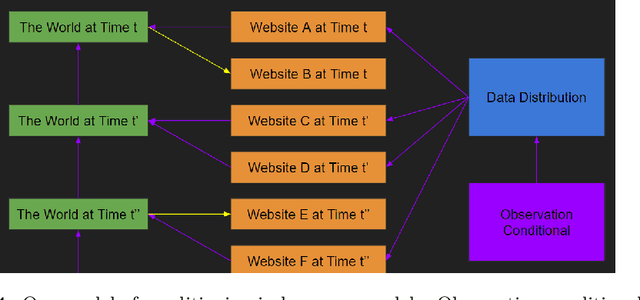
Our intention is to provide a definitive reference on what it would take to safely make use of generative/predictive models in the absence of a solution to the Eliciting Latent Knowledge problem. Furthermore, we believe that large language models can be understood as such predictive models of the world, and that such a conceptualization raises significant opportunities for their safe yet powerful use via carefully conditioning them to predict desirable outputs. Unfortunately, such approaches also raise a variety of potentially fatal safety problems, particularly surrounding situations where predictive models predict the output of other AI systems, potentially unbeknownst to us. There are numerous potential solutions to such problems, however, primarily via carefully conditioning models to predict the things we want (e.g. humans) rather than the things we don't (e.g. malign AIs). Furthermore, due to the simplicity of the prediction objective, we believe that predictive models present the easiest inner alignment problem that we are aware of. As a result, we think that conditioning approaches for predictive models represent the safest known way of eliciting human-level and slightly superhuman capabilities from large language models and other similar future models.