 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Streamlined Attention-Based Network for Descriptor Extraction
Jan 19, 2026We introduce SANDesc, a Streamlined Attention-Based Network for Descriptor extraction that aims to improve on existing architectures for keypoint description. Our descriptor network learns to compute descriptors that improve matching without modifying the underlying keypoint detector. We employ a revised U-Net-like architecture enhanced with Convolutional Block Attention Modules and residual paths, enabling effective local representation while maintaining computational efficiency. We refer to the building blocks of our model as Residual U-Net Blocks with Attention. The model is trained using a modified triplet loss in combination with a curriculum learning-inspired hard negative mining strategy, which improves training stability. Extensive experiments on HPatches, MegaDepth-1500, and the Image Matching Challenge 2021 show that training SANDesc on top of existing keypoint detectors leads to improved results on multiple matching tasks compared to the original keypoint descriptors. At the same time, SANDesc has a model complexity of just 2.4 million parameters. As a further contribution, we introduce a new urban dataset featuring 4K images and pre-calibrated intrinsics, designed to evaluate feature extractors. On this benchmark, SANDesc achieves substantial performance gains over the existing descriptors while operating with limited computational resources.
GMM-IKRS: Gaussian Mixture Models for Interpretable Keypoint Refinement and Scoring
Aug 30, 2024



The extraction of keypoints in images is at the basis of many computer vision applications, from localization to 3D reconstruction. Keypoints come with a score permitting to rank them according to their quality. While learned keypoints often exhibit better properties than handcrafted ones, their scores are not easily interpretable, making it virtually impossible to compare the quality of individual keypoints across methods. We propose a framework that can refine, and at the same time characterize with an interpretable score, the keypoints extracted by any method. Our approach leverages a modified robust Gaussian Mixture Model fit designed to both reject non-robust keypoints and refine the remaining ones. Our score comprises two components: one relates to the probability of extracting the same keypoint in an image captured from another viewpoint, the other relates to the localization accuracy of the keypoint. These two interpretable components permit a comparison of individual keypoints extracted across different methods. Through extensive experiments we demonstrate that, when applied to popular keypoint detectors, our framework consistently improves the repeatability of keypoints as well as their performance in homography and two/multiple-view pose recovery tasks.
S-TREK: Sequential Translation and Rotation Equivariant Keypoints for local feature extraction
Aug 28, 2023



In this work we introduce S-TREK, a novel local feature extractor that combines a deep keypoint detector, which is both translation and rotation equivariant by design, with a lightweight deep descriptor extractor. We train the S-TREK keypoint detector within a framework inspired by reinforcement learning, where we leverage a sequential procedure to maximize a reward directly related to keypoint repeatability. Our descriptor network is trained following a "detect, then describe" approach, where the descriptor loss is evaluated only at those locations where keypoints have been selected by the already trained detector. Extensive experiments on multiple benchmarks confirm the effectiveness of our proposed method, with S-TREK often outperforming other state-of-the-art methods in terms of repeatability and quality of the recovered poses, especially when dealing with in-plane rotations.
DELS-MVS: Deep Epipolar Line Search for Multi-View Stereo
Dec 13, 2022



We propose a novel approach for deep learning-based Multi-View Stereo (MVS). For each pixel in the reference image, our method leverages a deep architecture to search for the corresponding point in the source image directly along the corresponding epipolar line. We denote our method DELS-MVS: Deep Epipolar Line Search Multi-View Stereo. Previous works in deep MVS select a range of interest within the depth space, discretize it, and sample the epipolar line according to the resulting depth values: this can result in an uneven scanning of the epipolar line, hence of the image space. Instead, our method works directly on the epipolar line: this guarantees an even scanning of the image space and avoids both the need to select a depth range of interest, which is often not known a priori and can vary dramatically from scene to scene, and the need for a suitable discretization of the depth space. In fact, our search is iterative, which avoids the building of a cost volume, costly both to store and to process. Finally, our method performs a robust geometry-aware fusion of the estimated depth maps, leveraging a confidence predicted alongside each depth. We test DELS-MVS on the ETH3D, Tanks and Temples and DTU benchmarks and achieve competitive results with respect to state-of-the-art approaches.
MD-Net: Multi-Detector for Local Feature Extraction
Aug 10, 2022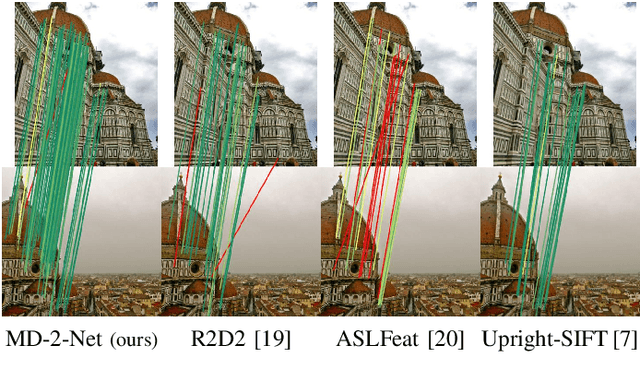
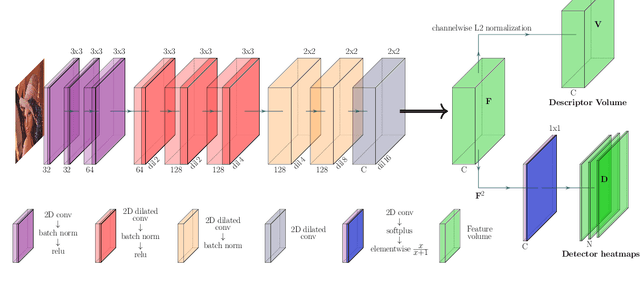
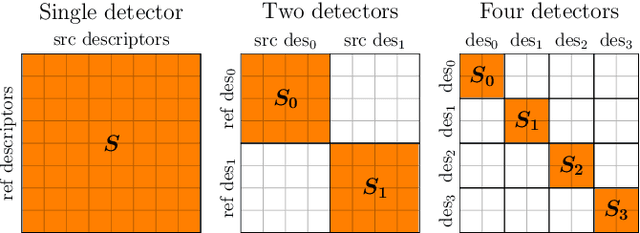

Establishing a sparse set of keypoint correspon dences between images is a fundamental task in many computer vision pipelines. Often, this translates into a computationally expensive nearest neighbor search, where every keypoint descriptor at one image must be compared with all the descriptors at the others. In order to lower the computational cost of the matching phase, we propose a deep feature extraction network capable of detecting a predefined number of complementary sets of keypoints at each image. Since only the descriptors within the same set need to be compared across the different images, the matching phase computational complexity decreases with the number of sets. We train our network to predict the keypoints and compute the corresponding descriptors jointly. In particular, in order to learn complementary sets of keypoints, we introduce a novel unsupervised loss which penalizes intersections among the different sets. Additionally, we propose a novel descriptor-based weighting scheme meant to penalize the detection of keypoints with non-discriminative descriptors. With extensive experiments we show that our feature extraction network, trained only on synthetically warped images and in a fully unsupervised manner, achieves competitive results on 3D reconstruction and re-localization tasks at a reduced matching complexity.