 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcateNet: Dialogue Separation Using Local And Global Feature Concatenation
Aug 16, 2024

Dialogue separation involves isolating a dialogue signal from a mixture, such as a movie or a TV program. This can be a necessary step to enable dialogue enhancement for broadcast-related applications. In this paper, ConcateNet for dialogue separation is proposed, which is based on a novel approach for processing local and global features aimed at better generalization for out-of-domain signals. ConcateNet is trained using a noise reduction-focused, publicly available dataset and evaluated using three datasets: two noise reduction-focused datasets (in-domain), which show competitive performance for ConcateNet, and a broadcast-focused dataset (out-of-domain), which verifies the better generalization performance for the proposed architecture compared to considered state-of-the-art noise-reduction methods.
Low-Resource Text-to-Speech Using Specific Data and Noise Augmentation
Jun 16, 2023



Many neural text-to-speech architectures can synthesize nearly natural speech from text inputs. These architectures must be trained with tens of hours of annotated and high-quality speech data. Compiling such large databases for every new voice requires a lot of time and effort. In this paper, we describe a method to extend the popular Tacotron-2 architecture and its training with data augmentation to enable single-speaker synthesis using a limited amount of specific training data. In contrast to elaborate augmentation methods proposed in the literature, we use simple stationary noises for data augmentation. Our extension is easy to implement and adds almost no computational overhead during training and inference. Using only two hours of training data, our approach was rated by human listeners to be on par with the baseline Tacotron-2 trained with 23.5 hours of LJSpeech data. In addition, we tested our model with a semantically unpredictable sentences test, which showed that both models exhibit similar intelligibility levels.
Predicting Preferred Dialogue-to-Background Loudness Difference in Dialogue-Separated Audio
May 31, 2023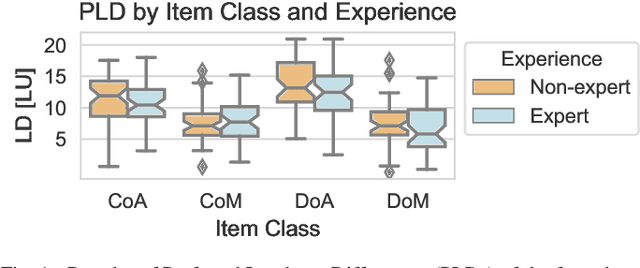


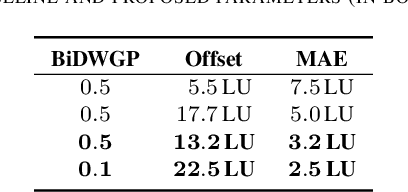
Dialogue Enhancement (DE) enables the rebalancing of dialogue and background sounds to fit personal preferences and needs in the context of broadcast audio. When individual audio stems are unavailable from production, Dialogue Separation (DS) can be applied to the final audio mixture to obtain estimates of these stems. This work focuses on Preferred Loudness Differences (PLDs) between dialogue and background sounds. While previous studies determined the PLD through a listening test employing original stems from production, stems estimated by DS are used in the present study. In addition, a larger variety of signal classes is considered. PLDs vary substantially across individuals (average interquartile range: 5.7 LU). Despite this variability, PLDs are found to be highly dependent on the signal type under consideration, and it is shown that median PLDs can be predicted using objective intelligibility metrics. Two existing baseline prediction methods - intended for use with original stems - displayed a Mean Absolute Error (MAE) of 7.5 LU and 5 LU, respectively. A modified baseline (MAE: 3.2 LU) and an alternative approach (MAE: 2.5 LU) are proposed. Results support the viability of processing final broadcast mixtures with DS and offering an alternative remixing that accounts for median PLDs.
Virtual Analog Modeling of Distortion Circuits Using Neural Ordinary Differential Equations
May 04, 2022
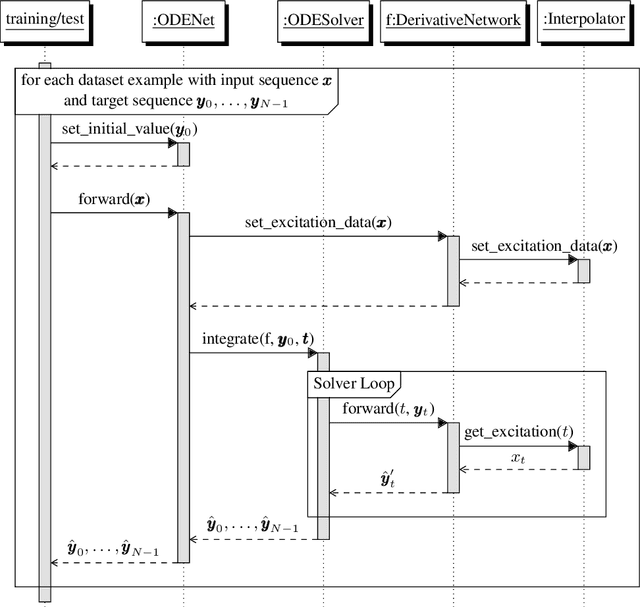

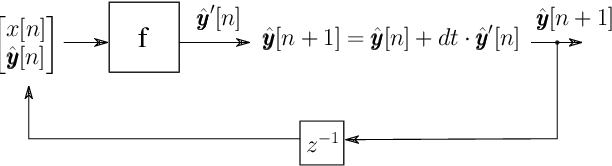
Recent research in deep learning has shown that neural networks can learn differential equations governing dynamical systems. In this paper, we adapt this concept to Virtual Analog (VA) modeling to learn the ordinary differential equations (ODEs) governing the first-order and the second-order diode clipper. The proposed models achieve performance comparable to state-of-the-art recurrent neural networks (RNNs) albeit using fewer parameters. We show that this approach does not require oversampling and allows to increase the sampling rate after the training has completed, which results in increased accuracy. Using a sophisticated numerical solver allows to increase the accuracy at the cost of slower processing. ODEs learned this way do not require closed forms but are still physically interpretable.