 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre there any 'object detectors' in the hidden layers of CNNs trained to identify objects or scenes?
Jul 02, 2020

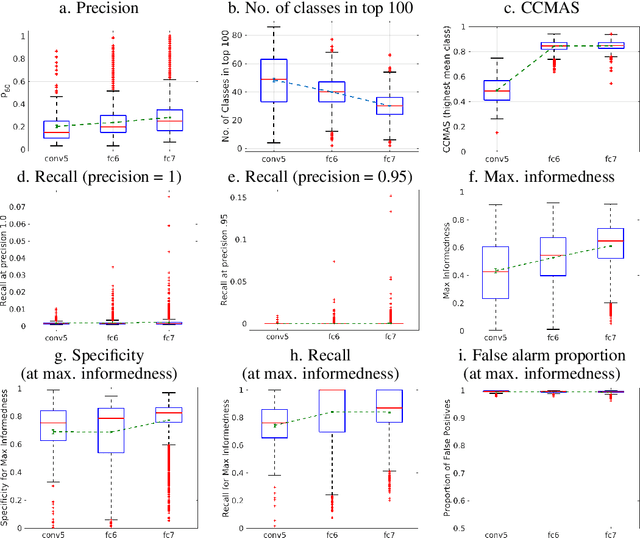
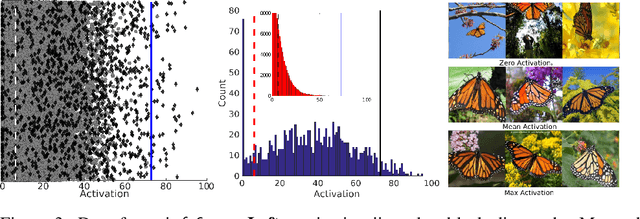
Various methods of measuring unit selectivity have been developed with the aim of better understanding how neural networks work. But the different measures provide divergent estimates of selectivity, and this has led to different conclusions regarding the conditions in which selective object representations are learned and the functional relevance of these representations. In an attempt to better characterize object selectivity, we undertake a comparison of various selectivity measures on a large set of units in AlexNet, including localist selectivity, precision, class-conditional mean activity selectivity (CCMAS), network dissection,the human interpretation of activation maximization (AM) images, and standard signal-detection measures. We find that the different measures provide different estimates of object selectivity, with precision and CCMAS measures providing misleadingly high estimates. Indeed, the most selective units had a poor hit-rate or a high false-alarm rate (or both) in object classification, making them poor object detectors. We fail to find any units that are even remotely as selective as the 'grandmother cell' units reported in recurrent neural networks. In order to generalize these results, we compared selectivity measures on units in VGG-16 and GoogLeNet trained on the ImageNet or Places-365 datasets that have been described as 'object detectors'. Again, we find poor hit-rates and high false-alarm rates for object classification. We conclude that signal-detection measures provide a better assessment of single-unit selectivity compared to common alternative approaches, and that deep convolutional networks of image classification do not learn object detectors in their hidden layers.
* Published in Vision Research 2020, 19 pages, 8 figures
When and where do feed-forward neural networks learn localist representations?
Jun 11, 2018
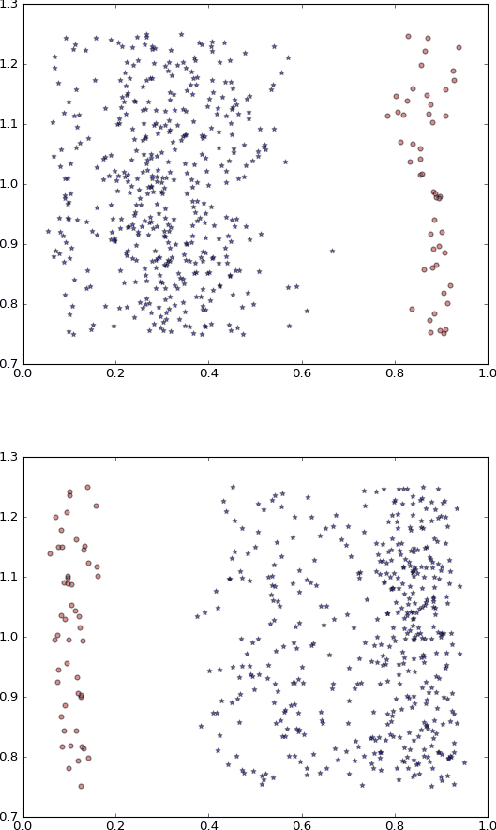
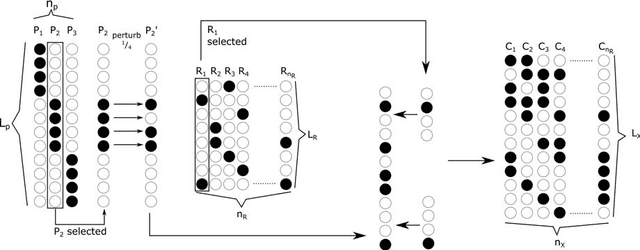
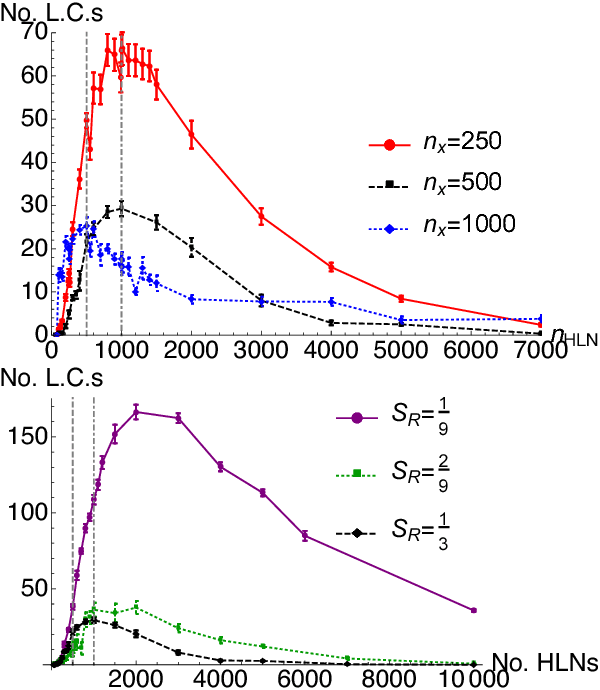
According to parallel distributed processing (PDP) theory in psychology, neural networks (NN) learn distributed rather than interpretable localist representations. This view has been held so strongly that few researchers have analysed single units to determine if this assumption is correct. However, recent results from psychology, neuroscience and computer science have shown the occasional existence of local codes emerging in artificial and biological neural networks. In this paper, we undertake the first systematic survey of when local codes emerge in a feed-forward neural network, using generated input and output data with known qualities. We find that the number of local codes that emerge from a NN follows a well-defined distribution across the number of hidden layer neurons, with a peak determined by the size of input data, number of examples presented and the sparsity of input data. Using a 1-hot output code drastically decreases the number of local codes on the hidden layer. The number of emergent local codes increases with the percentage of dropout applied to the hidden layer, suggesting that the localist encoding may offer a resilience to noisy networks. This data suggests that localist coding can emerge from feed-forward PDP networks and suggests some of the conditions that may lead to interpretable localist representations in the cortex. The findings highlight how local codes should not be dismissed out of hand.
Spiking memristor logic gates are a type of time-variant perceptron
Jan 08, 2018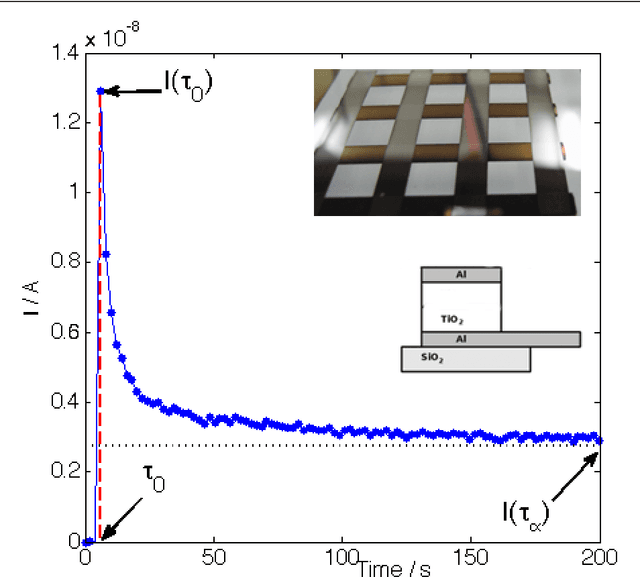
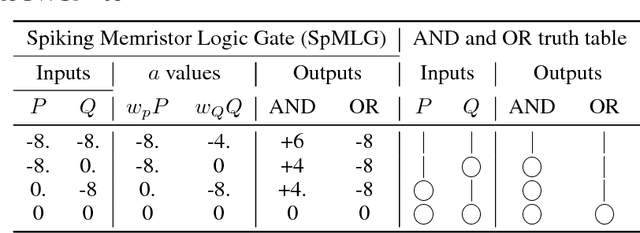
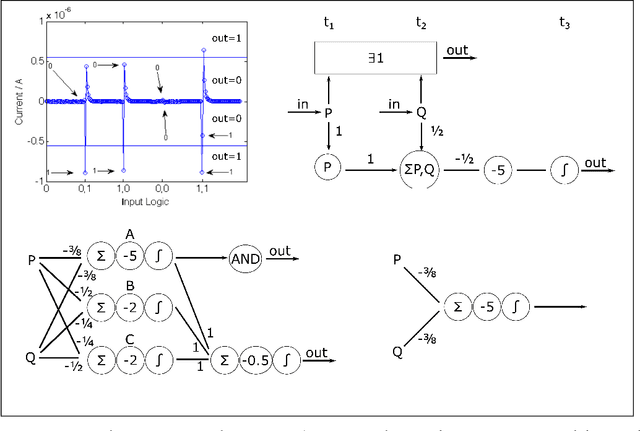
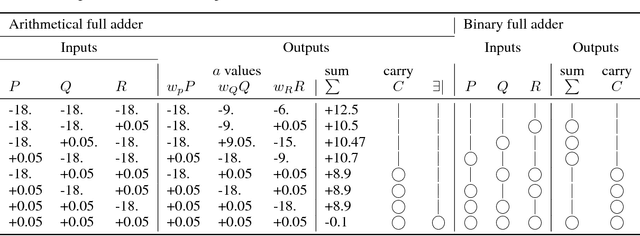
Memristors are low-power memory-holding resistors thought to be useful for neuromophic computing, which can compute via spike-interactions mediated through the device's short-term memory. Using interacting spikes, it is possible to build an AND gate that computes OR at the same time, similarly a full adder can be built that computes the arithmetical sum of its inputs. Here we show how these gates can be understood by modelling the memristors as a novel type of perceptron: one which is sensitive to input order. The memristor's memory can change the input weights for later inputs, and thus the memristor gates cannot be accurately described by a single perceptron, requiring either a network of time-invarient perceptrons or a complex time-varying self-reprogrammable perceptron. This work demonstrates the high functionality of memristor logic gates, and also that the addition of theasholding could enable the creation of a standard perceptron in hardware, which may have use in building neural net chips.