 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan Detection in Large Language Models: Insights from The Trojan Detection Challenge
Apr 21, 2024
Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, but their vulnerability to trojan or backdoor attacks poses significant security risks. This paper explores the challenges and insights gained from the Trojan Detection Competition 2023 (TDC2023), which focused on identifying and evaluating trojan attacks on LLMs. We investigate the difficulty of distinguishing between intended and unintended triggers, as well as the feasibility of reverse engineering trojans in real-world scenarios. Our comparative analysis of various trojan detection methods reveals that achieving high Recall scores is significantly more challenging than obtaining high Reverse-Engineering Attack Success Rate (REASR) scores. The top-performing methods in the competition achieved Recall scores around 0.16, comparable to a simple baseline of randomly sampling sentences from a distribution similar to the given training prefixes. This finding raises questions about the detectability and recoverability of trojans inserted into the model, given only the harmful targets. Despite the inability to fully solve the problem, the competition has led to interesting observations about the viability of trojan detection and improved techniques for optimizing LLM input prompts. The phenomenon of unintended triggers and the difficulty in distinguishing them from intended triggers highlights the need for further research into the robustness and interpretability of LLMs. The TDC2023 has provided valuable insights into the challenges and opportunities associated with trojan detection in LLMs, laying the groundwork for future research in this area to ensure their safety and reliability in real-world applications.
FairMixRep : Self-supervised Robust Representation Learning for Heterogeneous Data with Fairness constraints
Oct 14, 2020
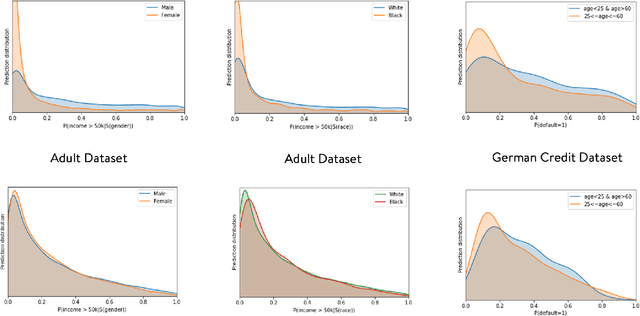

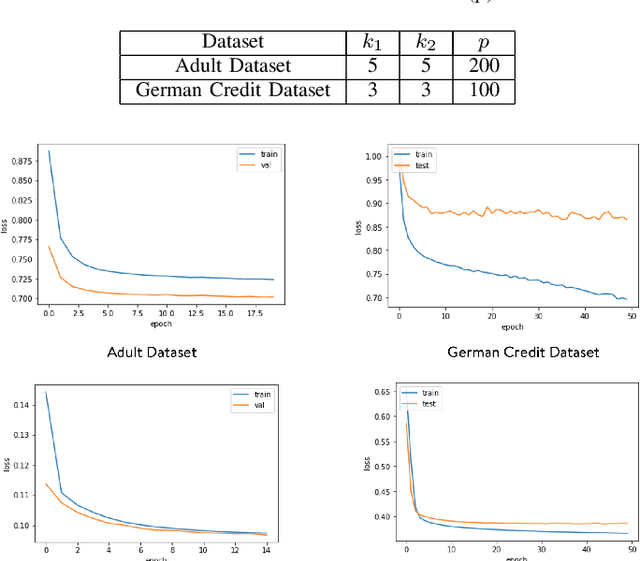
Representation Learning in a heterogeneous space with mixed variables of numerical and categorical types has interesting challenges due to its complex feature manifold. Moreover, feature learning in an unsupervised setup, without class labels and a suitable learning loss function, adds to the problem complexity. Further, the learned representation and subsequent predictions should not reflect discriminatory behavior towards certain sensitive groups or attributes. The proposed feature map should preserve maximum variations present in the data and needs to be fair with respect to the sensitive variables. We propose, in the first phase of our work, an efficient encoder-decoder framework to capture the mixed-domain information. The second phase of our work focuses on de-biasing the mixed space representations by adding relevant fairness constraints. This ensures minimal information loss between the representations before and after the fairness-preserving projections. Both the information content and the fairness aspect of the final representation learned has been validated through several metrics where it shows excellent performance. Our work (FairMixRep) addresses the problem of Mixed Space Fair Representation learning from an unsupervised perspective and learns a Universal representation that is timely, unique, and a novel research contribution.