 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Injection Attacks in Defended Systems
Jun 20, 2024Large language models play a crucial role in modern natural language processing technologies. However, their extensive use also introduces potential security risks, such as the possibility of black-box attacks. These attacks can embed hidden malicious features into the model, leading to adverse consequences during its deployment. This paper investigates methods for black-box attacks on large language models with a three-tiered defense mechanism. It analyzes the challenges and significance of these attacks, highlighting their potential implications for language processing system security. Existing attack and defense methods are examined, evaluating their effectiveness and applicability across various scenarios. Special attention is given to the detection algorithm for black-box attacks, identifying hazardous vulnerabilities in language models and retrieving sensitive information. This research presents a methodology for vulnerability detection and the development of defensive strategies against black-box attacks on large language models.
Trojan Detection in Large Language Models: Insights from The Trojan Detection Challenge
Apr 21, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, but their vulnerability to trojan or backdoor attacks poses significant security risks. This paper explores the challenges and insights gained from the Trojan Detection Competition 2023 (TDC2023), which focused on identifying and evaluating trojan attacks on LLMs. We investigate the difficulty of distinguishing between intended and unintended triggers, as well as the feasibility of reverse engineering trojans in real-world scenarios. Our comparative analysis of various trojan detection methods reveals that achieving high Recall scores is significantly more challenging than obtaining high Reverse-Engineering Attack Success Rate (REASR) scores. The top-performing methods in the competition achieved Recall scores around 0.16, comparable to a simple baseline of randomly sampling sentences from a distribution similar to the given training prefixes. This finding raises questions about the detectability and recoverability of trojans inserted into the model, given only the harmful targets. Despite the inability to fully solve the problem, the competition has led to interesting observations about the viability of trojan detection and improved techniques for optimizing LLM input prompts. The phenomenon of unintended triggers and the difficulty in distinguishing them from intended triggers highlights the need for further research into the robustness and interpretability of LLMs. The TDC2023 has provided valuable insights into the challenges and opportunities associated with trojan detection in LLMs, laying the groundwork for future research in this area to ensure their safety and reliability in real-world applications.
Uncertainty-Aware Evaluation for Vision-Language Models
Feb 24, 2024Vision-Language Models like GPT-4, LLaVA, and CogVLM have surged in popularity recently due to their impressive performance in several vision-language tasks. Current evaluation methods, however, overlook an essential component: uncertainty, which is crucial for a comprehensive assessment of VLMs. Addressing this oversight, we present a benchmark incorporating uncertainty quantification into evaluating VLMs. Our analysis spans 20+ VLMs, focusing on the multiple-choice Visual Question Answering (VQA) task. We examine models on 5 datasets that evaluate various vision-language capabilities. Using conformal prediction as an uncertainty estimation approach, we demonstrate that the models' uncertainty is not aligned with their accuracy. Specifically, we show that models with the highest accuracy may also have the highest uncertainty, which confirms the importance of measuring it for VLMs. Our empirical findings also reveal a correlation between model uncertainty and its language model part.
DIALOG-22 RuATD Generated Text Detection
Jun 16, 2022
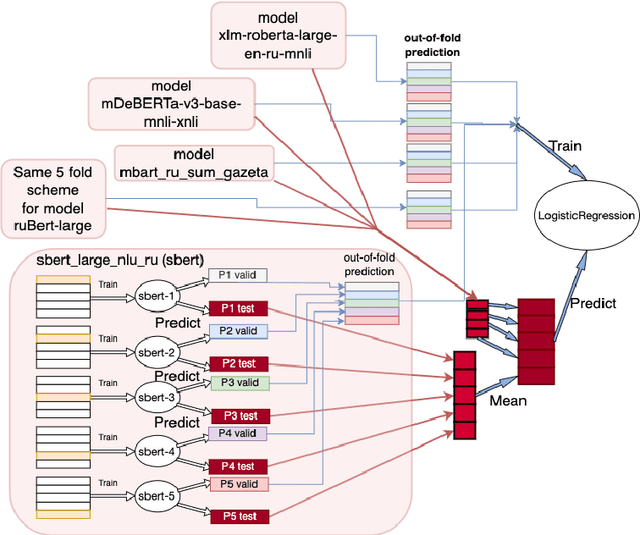


Text Generation Models (TGMs) succeed in creating text that matches human language style reasonably well. Detectors that can distinguish between TGM-generated text and human-written ones play an important role in preventing abuse of TGM. In this paper, we describe our pipeline for the two DIALOG-22 RuATD tasks: detecting generated text (binary task) and classification of which model was used to generate text (multiclass task). We achieved 1st place on the binary classification task with an accuracy score of 0.82995 on the private test set and 4th place on the multiclass classification task with an accuracy score of 0.62856 on the private test set. We proposed an ensemble method of different pre-trained models based on the attention mechanism.