 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Neural Network Verification with Tensor Parallelism and Fully Sharded Data Parallelism
Jun 09, 2026Formal neural network verification -- proving that a network satisfies safety properties for *all* inputs in a specified domain -- is bounded in practice by GPU memory: standard implementations of bound-propagation algorithms (IBP, CROWN, $α$-CROWN) require weight and relaxation-coefficient matrices to reside entirely on one accelerator. We adapt two parallelism techniques originally developed for large-scale model training to the auto_LiRPA / $α,β$-CROWN verification framework. Tensor Parallelism (TP) shards both weight and $A$-matrices across GPUs, achieving ${\approx}2\times$ peak-memory reduction at $P{=}2$; soundness is confirmed on VNN-COMP 2022 MNIST-FC benchmarks, though bound tightness degrades with the number of sharded zones due to forced IBP substitution for intermediate bounds inside sharded zones. Fully Sharded Data Parallelism (FSDP) shards only weight matrices with a per-layer AllGather, producing bounds that are bitwise identical to the single-GPU baseline: baseline memory drops by 80--90%, peak memory by 34--39% on wide MLPs. FSDP integrates cleanly with complete verification ($β$-CROWN + Branch-and-Bound) and with convolutional layers (BoundConv); a complete unsat result is obtained for CIFAR-100 ResNet-large (VNN-COMP 2024) under FSDP. Across all experiments the memory bottleneck in $α$-CROWN+BaB mode proves to be per-neuron alpha tensors, not weight matrices, pointing to the key direction for future work.
SafeAgent: A Runtime Protection Architecture for Agentic Systems
Apr 19, 2026Large language model (LLM) agents are vulnerable to prompt-injection attacks that propagate through multi-step workflows, tool interactions, and persistent context, making input-output filtering alone insufficient for reliable protection. This paper presents SafeAgent, a runtime security architecture that treats agent safety as a stateful decision problem over evolving interaction trajectories. The proposed design separates execution governance from semantic risk reasoning through two coordinated components: a runtime controller that mediates actions around the agent loop and a context-aware decision core that operates over persistent session state. The core is formalized as a context-aware advanced machine intelligence and instantiated through operators for risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, and state synchronization. Experiments on Agent Security Bench (ASB) and InjecAgent show that SafeAgent consistently improves robustness over baseline and text-level guardrail methods while maintaining competitive benign-task performance. Ablation studies further show that recovery confidence and policy weighting determine distinct safety-utility operating points.
Uncertainty-Aware Evaluation for Vision-Language Models
Feb 24, 2024Vision-Language Models like GPT-4, LLaVA, and CogVLM have surged in popularity recently due to their impressive performance in several vision-language tasks. Current evaluation methods, however, overlook an essential component: uncertainty, which is crucial for a comprehensive assessment of VLMs. Addressing this oversight, we present a benchmark incorporating uncertainty quantification into evaluating VLMs. Our analysis spans 20+ VLMs, focusing on the multiple-choice Visual Question Answering (VQA) task. We examine models on 5 datasets that evaluate various vision-language capabilities. Using conformal prediction as an uncertainty estimation approach, we demonstrate that the models' uncertainty is not aligned with their accuracy. Specifically, we show that models with the highest accuracy may also have the highest uncertainty, which confirms the importance of measuring it for VLMs. Our empirical findings also reveal a correlation between model uncertainty and its language model part.
DIALOG-22 RuATD Generated Text Detection
Jun 16, 2022
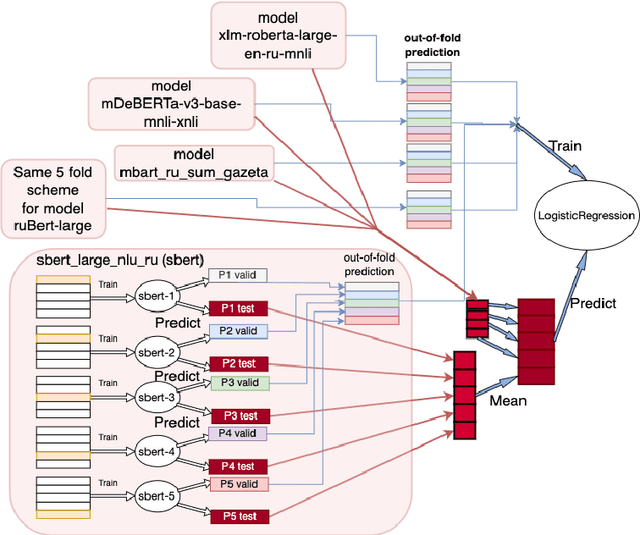


Text Generation Models (TGMs) succeed in creating text that matches human language style reasonably well. Detectors that can distinguish between TGM-generated text and human-written ones play an important role in preventing abuse of TGM. In this paper, we describe our pipeline for the two DIALOG-22 RuATD tasks: detecting generated text (binary task) and classification of which model was used to generate text (multiclass task). We achieved 1st place on the binary classification task with an accuracy score of 0.82995 on the private test set and 4th place on the multiclass classification task with an accuracy score of 0.62856 on the private test set. We proposed an ensemble method of different pre-trained models based on the attention mechanism.