 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIALOG-22 RuATD Generated Text Detection
Paper and Code

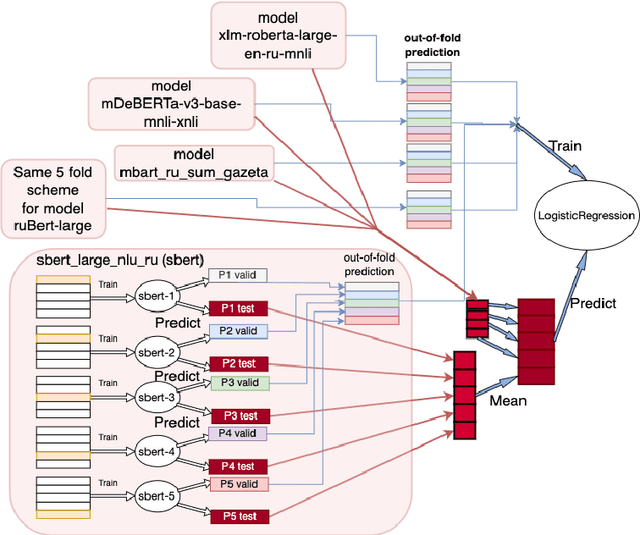


Text Generation Models (TGMs) succeed in creating text that matches human language style reasonably well. Detectors that can distinguish between TGM-generated text and human-written ones play an important role in preventing abuse of TGM. In this paper, we describe our pipeline for the two DIALOG-22 RuATD tasks: detecting generated text (binary task) and classification of which model was used to generate text (multiclass task). We achieved 1st place on the binary classification task with an accuracy score of 0.82995 on the private test set and 4th place on the multiclass classification task with an accuracy score of 0.62856 on the private test set. We proposed an ensemble method of different pre-trained models based on the attention mechanism.