 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multiple Diverse Hypotheses for Human 3D Pose Consistent with 2D Joint Detections
Aug 20, 2017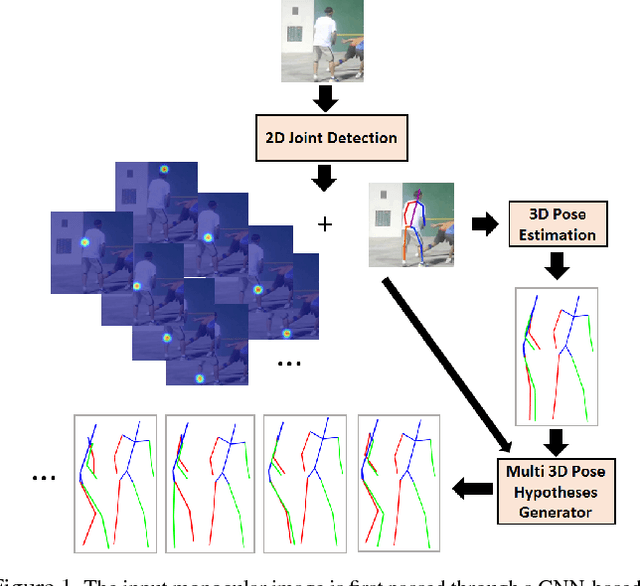
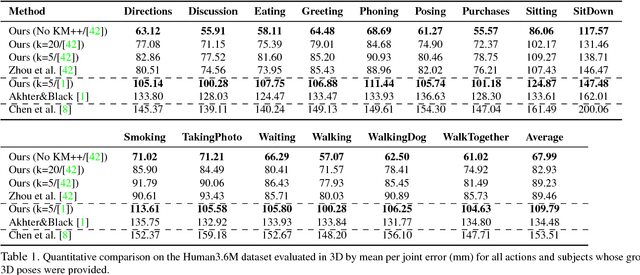
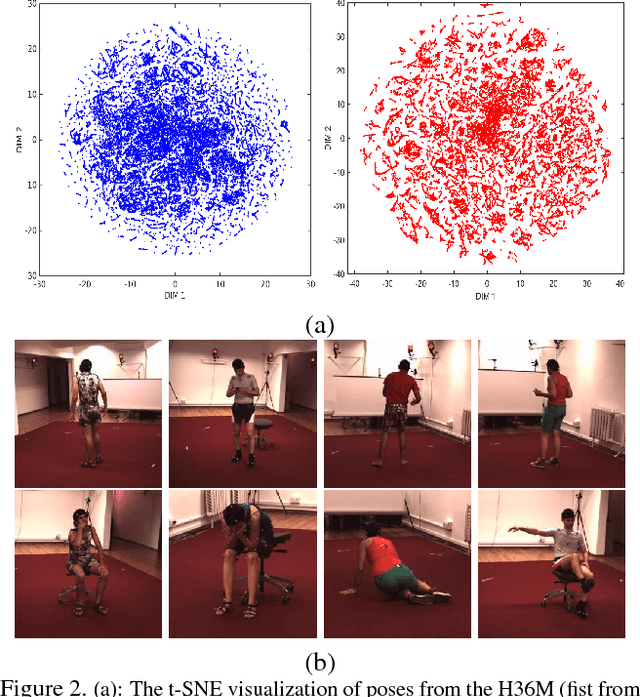

We propose a method to generate multiple diverse and valid human pose hypotheses in 3D all consistent with the 2D detection of joints in a monocular RGB image. We use a novel generative model uniform (unbiased) in the space of anatomically plausible 3D poses. Our model is compositional (produces a pose by combining parts) and since it is restricted only by anatomical constraints it can generalize to every plausible human 3D pose. Removing the model bias intrinsically helps to generate more diverse 3D pose hypotheses. We argue that generating multiple pose hypotheses is more reasonable than generating only a single 3D pose based on the 2D joint detection given the depth ambiguity and the uncertainty due to occlusion and imperfect 2D joint detection. We hope that the idea of generating multiple consistent pose hypotheses can give rise to a new line of future work that has not received much attention in the literature. We used the Human3.6M dataset for empirical evaluation.
Information Pursuit: A Bayesian Framework for Sequential Scene Parsing
Jan 09, 2017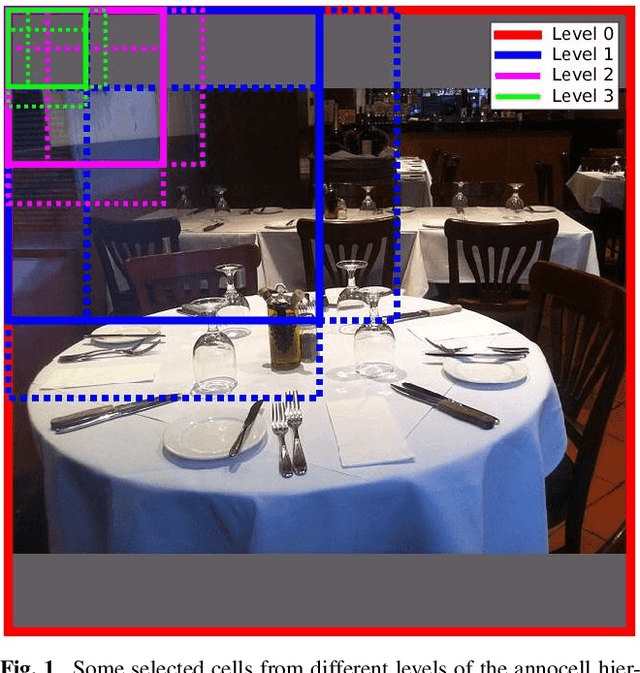
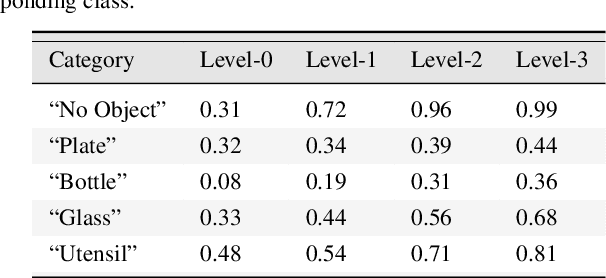

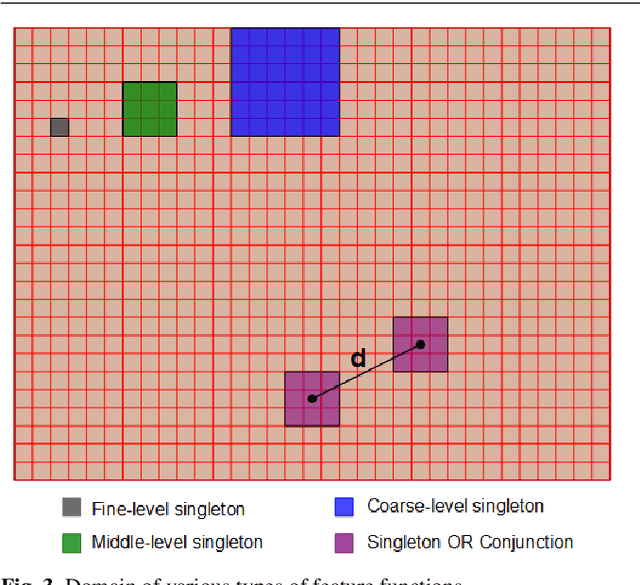
Despite enormous progress in object detection and classification, the problem of incorporating expected contextual relationships among object instances into modern recognition systems remains a key challenge. In this work we propose Information Pursuit, a Bayesian framework for scene parsing that combines prior models for the geometry of the scene and the spatial arrangement of objects instances with a data model for the output of high-level image classifiers trained to answer specific questions about the scene. In the proposed framework, the scene interpretation is progressively refined as evidence accumulates from the answers to a sequence of questions. At each step, we choose the question to maximize the mutual information between the new answer and the full interpretation given the current evidence obtained from previous inquiries. We also propose a method for learning the parameters of the model from synthesized, annotated scenes obtained by top-down sampling from an easy-to-learn generative scene model. Finally, we introduce a database of annotated indoor scenes of dining room tables, which we use to evaluate the proposed approach.