 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePex: Memory-efficient Microcontroller Deep Learning through Partial Execution
Nov 30, 2022
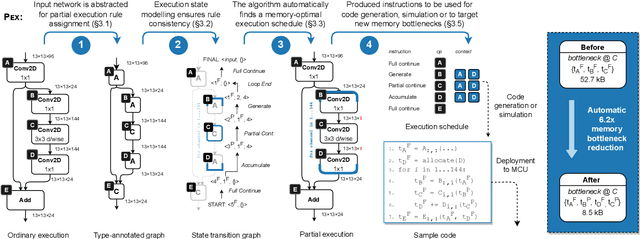
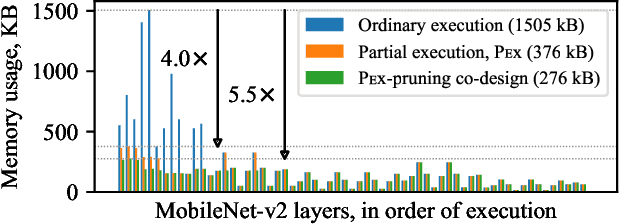

Embedded and IoT devices, largely powered by microcontroller units (MCUs), could be made more intelligent by leveraging on-device deep learning. One of the main challenges of neural network inference on an MCU is the extremely limited amount of read-write on-chip memory (SRAM, < 512 kB). SRAM is consumed by the neural network layer (operator) input and output buffers, which, traditionally, must be in memory (materialised) for an operator to execute. We discuss a novel execution paradigm for microcontroller deep learning, which modifies the execution of neural networks to avoid materialising full buffers in memory, drastically reducing SRAM usage with no computation overhead. This is achieved by exploiting the properties of operators, which can consume/produce a fraction of their input/output at a time. We describe a partial execution compiler, Pex, which produces memory-efficient execution schedules automatically by identifying subgraphs of operators whose execution can be split along the feature ("channel") dimension. Memory usage is reduced further by targeting memory bottlenecks with structured pruning, leading to the co-design of the network architecture and its execution schedule. Our evaluation of image and audio classification models: (a) establishes state-of-the-art performance in low SRAM usage regimes for considered tasks with up to +2.9% accuracy increase; (b) finds that a 4x memory reduction is possible by applying partial execution alone, or up to 10.5x when using the compiler-pruning co-design, while maintaining the classification accuracy compared to prior work; (c) uses the recovered SRAM to process higher resolution inputs instead, increasing accuracy by up to +3.9% on Visual Wake Words.
Differentiable Network Pruning for Microcontrollers
Oct 15, 2021

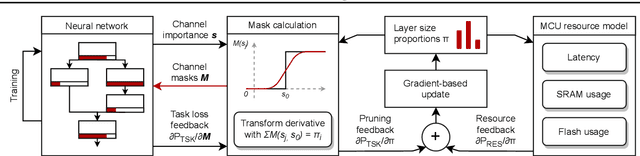

Embedded and personal IoT devices are powered by microcontroller units (MCUs), whose extreme resource scarcity is a major obstacle for applications relying on on-device deep learning inference. Orders of magnitude less storage, memory and computational capacity, compared to what is typically required to execute neural networks, impose strict structural constraints on the network architecture and call for specialist model compression methodology. In this work, we present a differentiable structured network pruning method for convolutional neural networks, which integrates a model's MCU-specific resource usage and parameter importance feedback to obtain highly compressed yet accurate classification models. Our methodology (a) improves key resource usage of models up to 80x; (b) prunes iteratively while a model is trained, resulting in little to no overhead or even improved training time; (c) produces compressed models with matching or improved resource usage up to 1.7x in less time compared to prior MCU-specific methods. Compressed models are available for download.
$μ$NAS: Constrained Neural Architecture Search for Microcontrollers
Nov 04, 2020

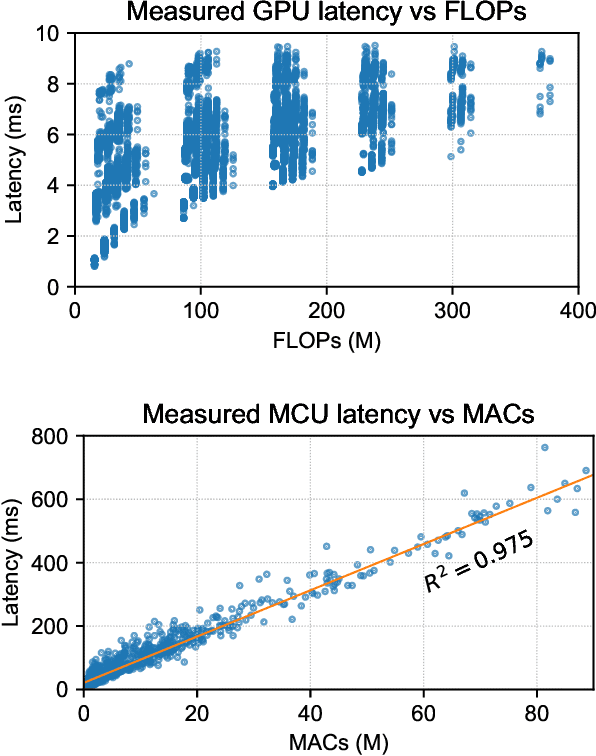

IoT devices are powered by microcontroller units (MCUs) which are extremely resource-scarce: a typical MCU may have an underpowered processor and around 64 KB of memory and persistent storage, which is orders of magnitude fewer computational resources than is typically required for deep learning. Designing neural networks for such a platform requires an intricate balance between keeping high predictive performance (accuracy) while achieving low memory and storage usage and inference latency. This is extremely challenging to achieve manually, so in this work, we build a neural architecture search (NAS) system, called $\mu$NAS, to automate the design of such small-yet-powerful MCU-level networks. $\mu$NAS explicitly targets the three primary aspects of resource scarcity of MCUs: the size of RAM, persistent storage and processor speed. $\mu$NAS represents a significant advance in resource-efficient models, especially for "mid-tier" MCUs with memory requirements ranging from 0.5 KB to 64 KB. We show that on a variety of image classification datasets $\mu$NAS is able to (a) improve top-1 classification accuracy by up to 4.8%, or (b) reduce memory footprint by 4--13x, or (c) reduce the number of multiply-accumulate operations by $\approx$900x, compared to existing MCU specialist literature and resource-efficient models.
The Final Frontier: Deep Learning in Space
Feb 03, 2020
Machine learning, particularly deep learning, is being increasing utilised in space applications, mirroring the groundbreaking success in many earthbound problems. Deploying a space device, e.g. a satellite, is becoming more accessible to small actors due to the development of modular satellites and commercial space launches, which fuels further growth of this area. Deep learning's ability to deliver sophisticated computational intelligence makes it an attractive option to facilitate various tasks on space devices and reduce operational costs. In this work, we identify deep learning in space as one of development directions for mobile and embedded machine learning. We collate various applications of machine learning to space data, such as satellite imaging, and describe how on-device deep learning can meaningfully improve the operation of a spacecraft, such as by reducing communication costs or facilitating navigation. We detail and contextualise compute platform of satellites and draw parallels with embedded systems and current research in deep learning for resource-constrained environments.
Neural networks on microcontrollers: saving memory at inference via operator reordering
Oct 02, 2019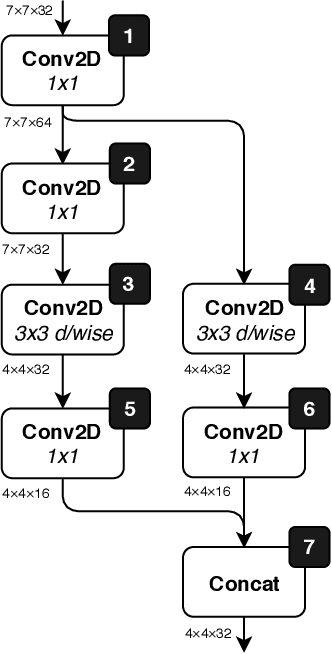

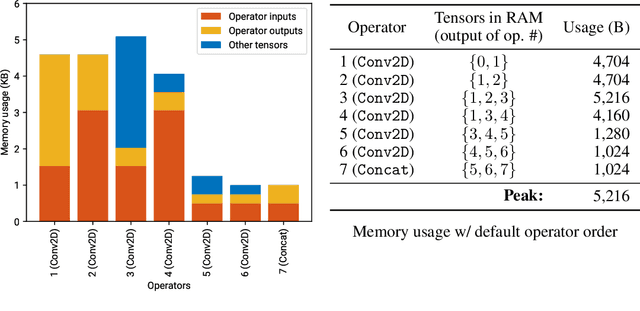
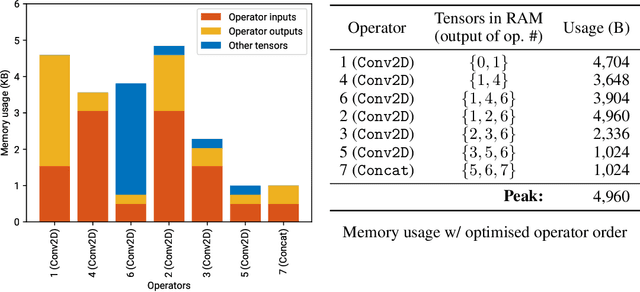
Designing deep learning models for highly-constrained hardware would allow imbuing many edge devices with intelligence. Microcontrollers (MCUs) are an attractive platform for building smart devices due to their low cost, wide availability, and modest power usage. However, they lack the computational resources to run neural networks as straightforwardly as mobile or server platforms, which necessitates changes to the network architecture and the inference software. In this work, we discuss the deployment and memory concerns of neural networks on MCUs and present a way of saving memory by changing the execution order of the network's operators, which is orthogonal to other compression methods. We publish a tool for reordering operators of TensorFlow Lite models and demonstrate its utility by sufficiently reducing the memory footprint of a CNN to deploy it on an MCU with 512KB SRAM.
Cross-modal Recurrent Models for Weight Objective Prediction from Multimodal Time-series Data
Nov 29, 2017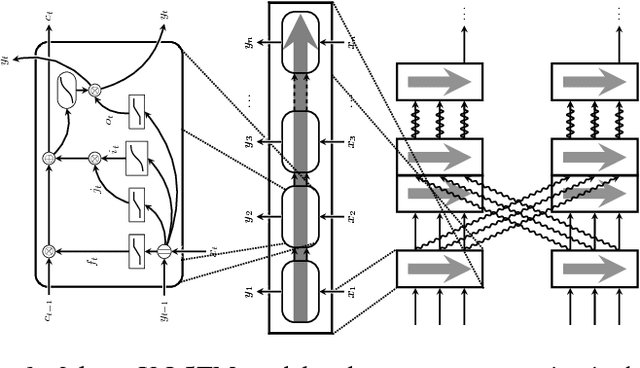
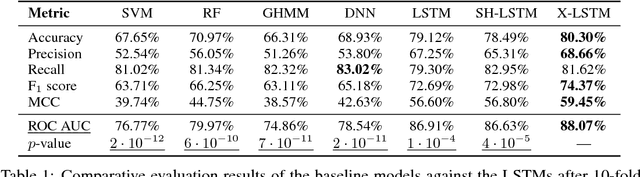
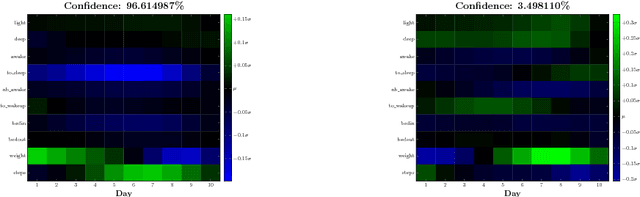

We analyse multimodal time-series data corresponding to weight, sleep and steps measurements. We focus on predicting whether a user will successfully achieve his/her weight objective. For this, we design several deep long short-term memory (LSTM) architectures, including a novel cross-modal LSTM (X-LSTM), and demonstrate their superiority over baseline approaches. The X-LSTM improves parameter efficiency by processing each modality separately and allowing for information flow between them by way of recurrent cross-connections. We present a general hyperparameter optimisation technique for X-LSTMs, which allows us to significantly improve on the LSTM and a prior state-of-the-art cross-modal approach, using a comparable number of parameters. Finally, we visualise the model's predictions, revealing implications about latent variables in this task.