 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Network Pruning for Microcontrollers
Paper and Code
Oct 15, 2021

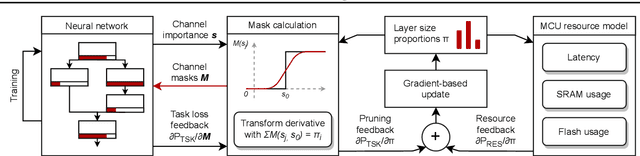

Embedded and personal IoT devices are powered by microcontroller units (MCUs), whose extreme resource scarcity is a major obstacle for applications relying on on-device deep learning inference. Orders of magnitude less storage, memory and computational capacity, compared to what is typically required to execute neural networks, impose strict structural constraints on the network architecture and call for specialist model compression methodology. In this work, we present a differentiable structured network pruning method for convolutional neural networks, which integrates a model's MCU-specific resource usage and parameter importance feedback to obtain highly compressed yet accurate classification models. Our methodology (a) improves key resource usage of models up to 80x; (b) prunes iteratively while a model is trained, resulting in little to no overhead or even improved training time; (c) produces compressed models with matching or improved resource usage up to 1.7x in less time compared to prior MCU-specific methods. Compressed models are available for download.