 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromotheus: An End-to-End Machine Learning Framework for Optimizing Markdown in Online Fashion E-commerce
Jul 03, 2022



Managing discount promotional events ("markdown") is a significant part of running an e-commerce business, and inefficiencies here can significantly hamper a retailer's profitability. Traditional approaches for tackling this problem rely heavily on price elasticity modelling. However, the partial information nature of price elasticity modelling, together with the non-negotiable responsibility for protecting profitability, mean that machine learning practitioners must often go through great lengths to define strategies for measuring offline model quality. In the face of this, many retailers fall back on rule-based methods, thus forgoing significant gains in profitability that can be captured by machine learning. In this paper, we introduce two novel end-to-end markdown management systems for optimising markdown at different stages of a retailer's journey. The first system, "Ithax", enacts a rational supply-side pricing strategy without demand estimation, and can be usefully deployed as a "cold start" solution to collect markdown data while maintaining revenue control. The second system, "Promotheus", presents a full framework for markdown optimization with price elasticity. We describe in detail the specific modelling and validation procedures that, within our experience, have been crucial to building a system that performs robustly in the real world. Both markdown systems achieve superior profitability compared to decisions made by our experienced operations teams in a controlled online test, with improvements of 86% (Promotheus) and 79% (Ithax) relative to manual strategies. These systems have been deployed to manage markdown at ASOS.com, and both systems can be fruitfully deployed for price optimization across a wide variety of retail e-commerce settings.
A Recurrent Neural Network Survival Model: Predicting Web User Return Time
Jul 11, 2018
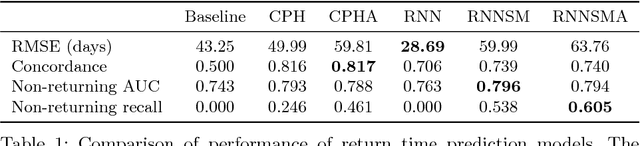
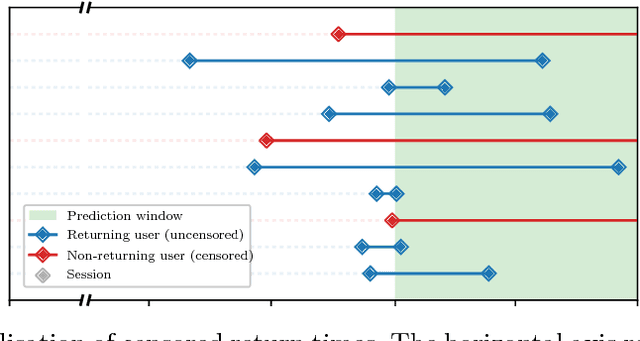
The size of a website's active user base directly affects its value. Thus, it is important to monitor and influence a user's likelihood to return to a site. Essential to this is predicting when a user will return. Current state of the art approaches to solve this problem come in two flavors: (1) Recurrent Neural Network (RNN) based solutions and (2) survival analysis methods. We observe that both techniques are severely limited when applied to this problem. Survival models can only incorporate aggregate representations of users instead of automatically learning a representation directly from a raw time series of user actions. RNNs can automatically learn features, but can not be directly trained with examples of non-returning users who have no target value for their return time. We develop a novel RNN survival model that removes the limitations of the state of the art methods. We demonstrate that this model can successfully be applied to return time prediction on a large e-commerce dataset with a superior ability to discriminate between returning and non-returning users than either method applied in isolation.
Generalising Random Forest Parameter Optimisation to Include Stability and Cost
Jul 13, 2017


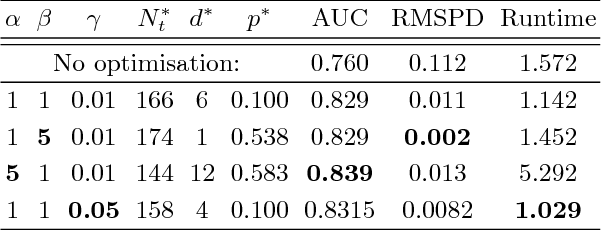
Random forests are among the most popular classification and regression methods used in industrial applications. To be effective, the parameters of random forests must be carefully tuned. This is usually done by choosing values that minimize the prediction error on a held out dataset. We argue that error reduction is only one of several metrics that must be considered when optimizing random forest parameters for commercial applications. We propose a novel metric that captures the stability of random forests predictions, which we argue is key for scenarios that require successive predictions. We motivate the need for multi-criteria optimization by showing that in practical applications, simply choosing the parameters that lead to the lowest error can introduce unnecessary costs and produce predictions that are not stable across independent runs. To optimize this multi-criteria trade-off, we present a new framework that efficiently finds a principled balance between these three considerations using Bayesian optimisation. The pitfalls of optimising forest parameters purely for error reduction are demonstrated using two publicly available real world datasets. We show that our framework leads to parameter settings that are markedly different from the values discovered by error reduction metrics.
* To appear in ECML-PKDD 2017