 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicitly Modeled Attention Maps for Image Classification
Jun 14, 2020

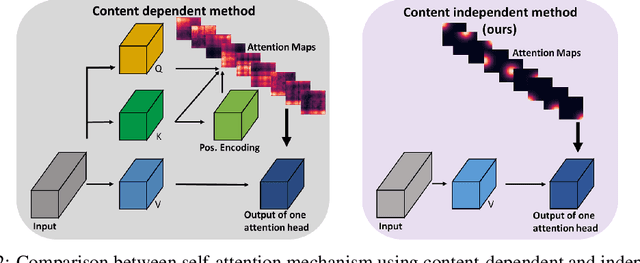
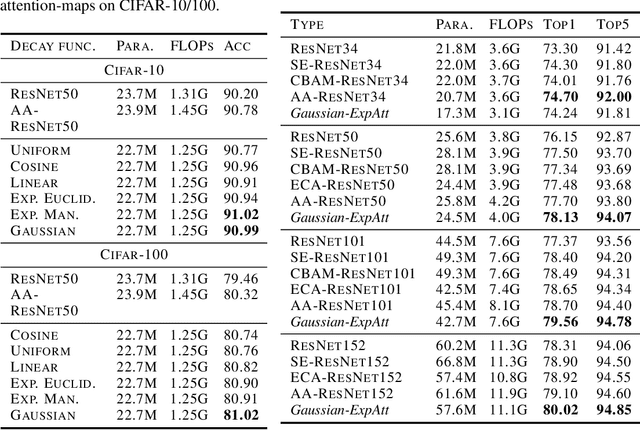
Self-attention networks have shown remarkable progress in computer vision tasks such as image classification. The main benefit of the self-attention mechanism is the ability to capture long-range feature interactions in attention-maps. However, the computation of attention-maps requires a learnable key, query, and positional encoding, whose usage is often not intuitive and computationally expensive. To mitigate this problem, we propose a novel self-attention module with explicitly modeled attention-maps using only a single learnable parameter for low computational overhead. The design of explicitly modeled attention-maps using geometric prior is based on the observation that the spatial context for a given pixel within an image is mostly dominated by its neighbors, while more distant pixels have a minor contribution. Concretely, the attention-maps are parametrized via simple functions (e.g., Gaussian kernel) with a learnable radius, which is modeled independently of the input content. Our evaluation shows that our method achieves an accuracy improvement of up to 2.2% over the ResNet-baselines in ImageNet ILSVRC and outperforms other self-attention methods such as AA-ResNet152 (Bello et al., 2019) in accuracy by 0.9% with 6.4% fewer parameters and 6.7% fewer GFLOPs.
SELF: Learning to Filter Noisy Labels with Self-Ensembling
Oct 04, 2019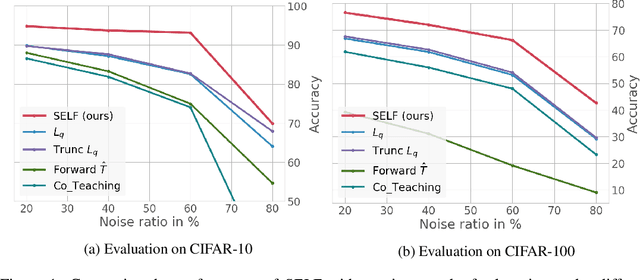
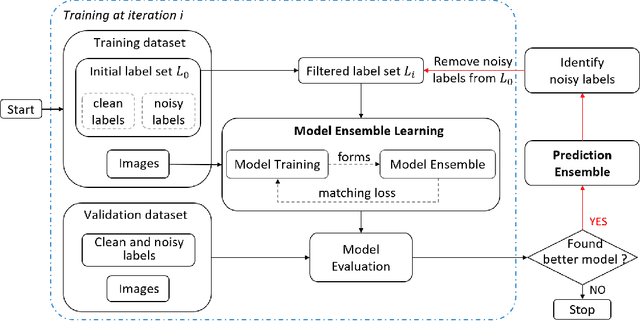
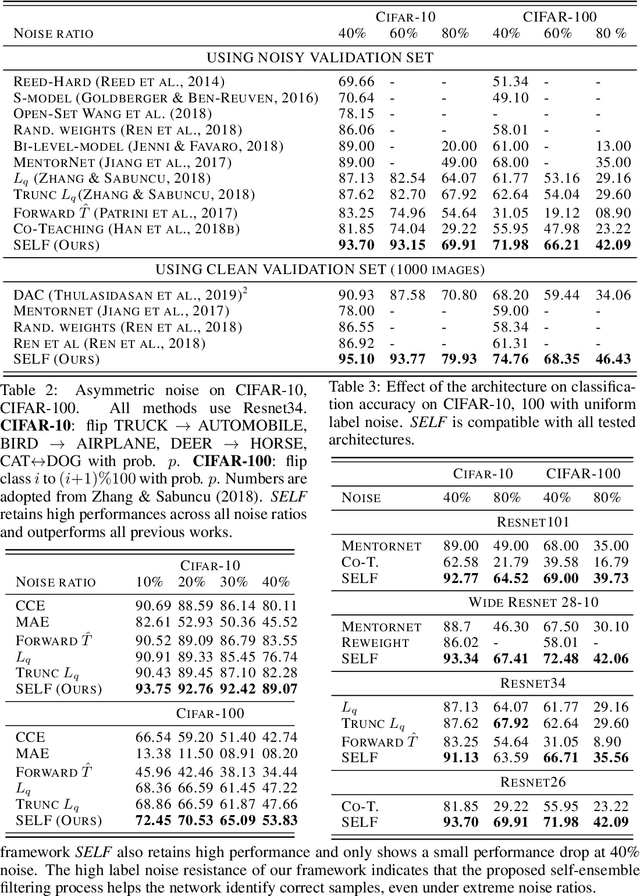

Deep neural networks (DNNs) have been shown to over-fit a dataset when being trained with noisy labels for a long enough time. To overcome this problem, we present a simple and effective method self-ensemble label filtering (SELF) to progressively filter out the wrong labels during training. Our method improves the task performance by gradually allowing supervision only from the potentially non-noisy (clean) labels and stops learning on the filtered noisy labels. For the filtering, we form running averages of predictions over the entire training dataset using the network output at different training epochs. We show that these ensemble estimates yield more accurate identification of inconsistent predictions throughout training than the single estimates of the network at the most recent training epoch. While filtered samples are removed entirely from the supervised training loss, we dynamically leverage them via semi-supervised learning in the unsupervised loss. We demonstrate the positive effect of such an approach on various image classification tasks under both symmetric and asymmetric label noise and at different noise ratios. It substantially outperforms all previous works on noise-aware learning across different datasets and can be applied to a broad set of network architectures.
DeepUSPS: Deep Robust Unsupervised Saliency Prediction With Self-Supervision
Sep 28, 2019
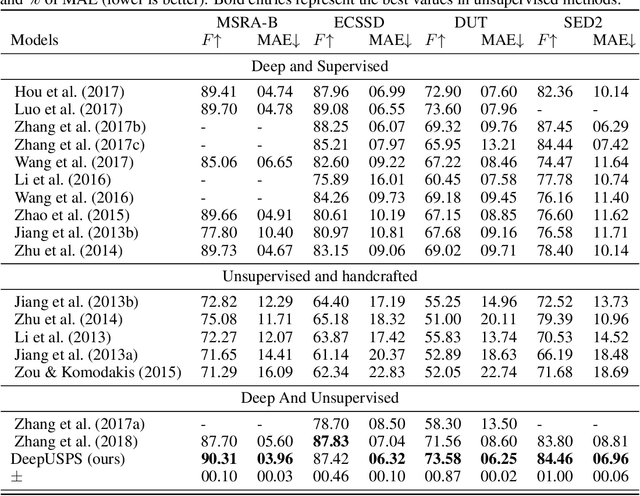

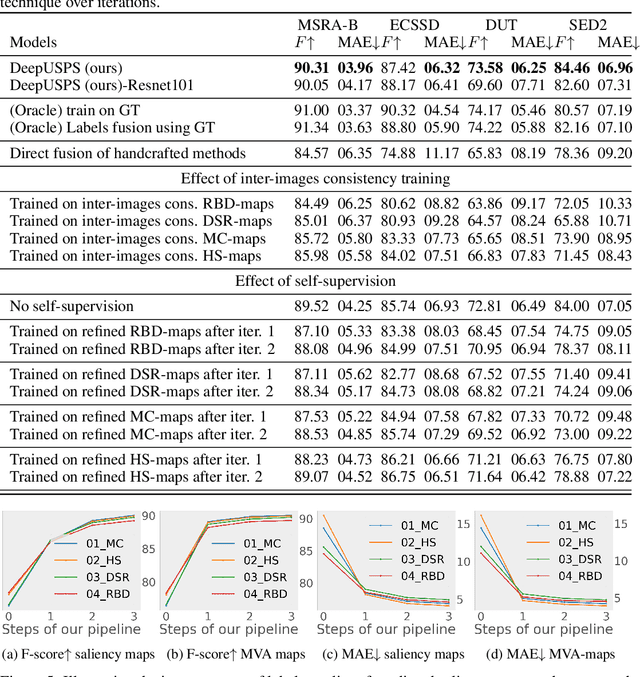
Deep neural network (DNN) based salient object detection in images based on high-quality labels is expensive. Alternative unsupervised approaches rely on careful selection of multiple handcrafted saliency methods to generate noisy pseudo-ground-truth labels.In this work, we propose a two-stage mechanism for robust unsupervised object saliency prediction, where the first stage involves refinement of the noisy pseudo-labels generated from different handcrafted methods.Each handcrafted method is substituted by a deep network that learns to generate the pseudo-labels. These labels are refined incrementally in multiple iterations via our proposed self-supervision technique. In the second stage, the refined labels produced from multiple networks representing multiple saliency methods are used to train the actual saliency detection network. We show that this self-learning procedure outperforms all the existing unsupervised methods over different datasets. Results are even comparable to those of fully-supervised state-of-the-art approaches.
Robust Learning Under Label Noise With Iterative Noise-Filtering
Jun 01, 2019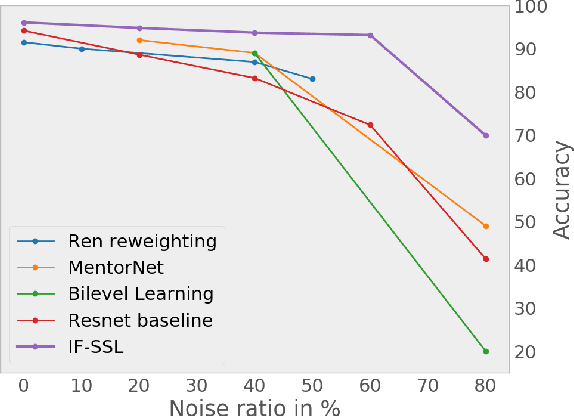
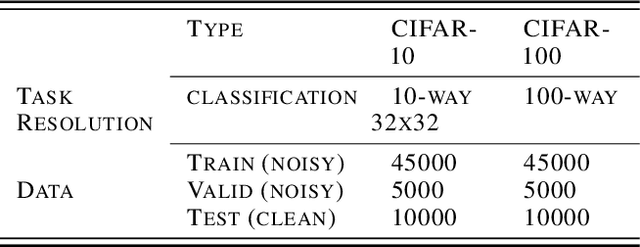
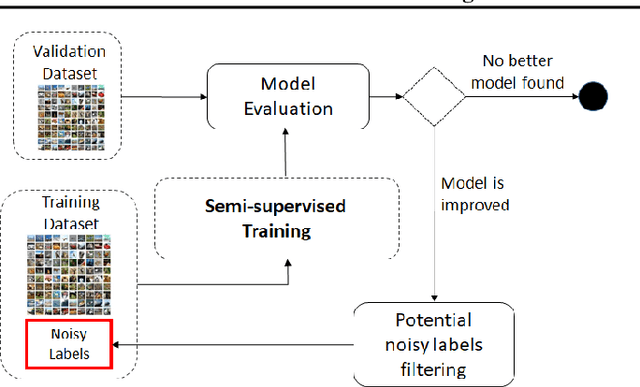
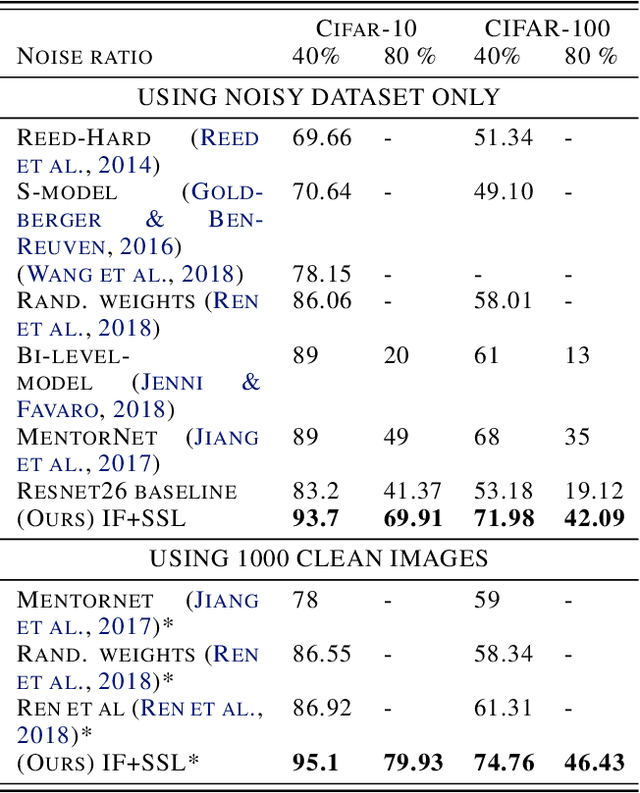
We consider the problem of training a model under the presence of label noise. Current approaches identify samples with potentially incorrect labels and reduce their influence on the learning process by either assigning lower weights to them or completely removing them from the training set. In the first case the model however still learns from noisy labels; in the latter approach, good training data can be lost. In this paper, we propose an iterative semi-supervised mechanism for robust learning which excludes noisy labels but is still able to learn from the corresponding samples. To this end, we add an unsupervised loss term that also serves as a regularizer against the remaining label noise. We evaluate our approach on common classification tasks with different noise ratios. Our robust models outperform the state-of-the-art methods by a large margin. Especially for very large noise ratios, we achieve up to 20 % absolute improvement compared to the previous best model.
Consistency-based anomaly detection with adaptive multiple-hypotheses predictions
Oct 31, 2018

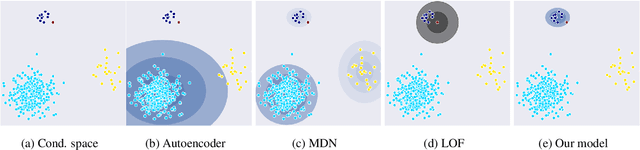
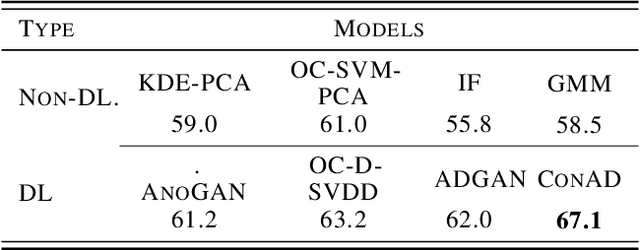
In out-of-distribution classification tasks, only some classes - the normal cases - can be modeled with data, whereas the variation of all possible anomalies is too large to be described sufficiently by samples. Thus, the wide-spread discriminative approaches cannot cover such learning tasks and rather generative models, which attempt to learn the input density of the ordinary cases, are used. However, generative models suffer under a large input dimensionality (as in images) and are typically inefficient learners. Motivated by the Local-Outlier-Factor (LOF) method, in this work, we propose to allow the network to directly estimate the local density functions since, for the detection of outliers, the local neighborhood is more important than the global one. At the same time, we retain consistency in the sense that the model must not support areas of the input space that are not covered by samples. Our method allows the model to identify out-of-distribution samples reliably. For the anomaly detection task on CIFAR-10, our ConAD model results in up to 5% points improvement over previously reported results.