 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSSED: a large-scale dataset and benchmark for speech emotion recognition
Jan 30, 2021
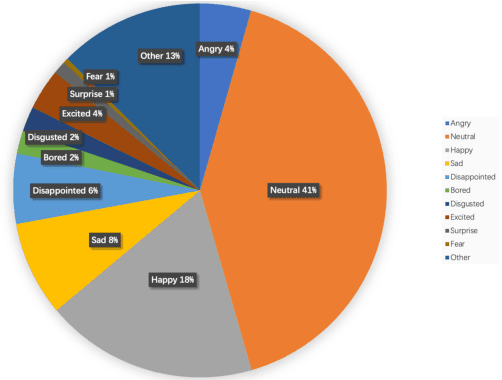


Speech emotion recognition is a vital contributor to the next generation of human-computer interaction (HCI). However, current existing small-scale databases have limited the development of related research. In this paper, we present LSSED, a challenging large-scale english speech emotion dataset, which has data collected from 820 subjects to simulate real-world distribution. In addition, we release some pre-trained models based on LSSED, which can not only promote the development of speech emotion recognition, but can also be transferred to related downstream tasks such as mental health analysis where data is extremely difficult to collect. Finally, our experiments show the necessity of large-scale datasets and the effectiveness of pre-trained models. The dateset will be released on https://github.com/tobefans/LSSED.