 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeES-Merging: Biological MLLM Merging via Embedding Space Signals
Mar 15, 2026Biological multimodal large language models (MLLMs) have emerged as powerful foundation models for scientific discovery. However, existing models are specialized to a single modality, limiting their ability to solve inherently cross-modal scientific problems. While model merging is an efficient method to combine the different modalities into a unified MLLM, existing methods rely on input-agnostic parameter space heuristics that fail to faithfully capture modality specialization. To overcome this limitation, we propose a representation-aware merging framework that estimates merging coefficients from embedding space signals. We first design a probe input that consists of different modality tokens and forward it through each specialized MLLM to obtain layer-wise embedding responses that reflect modality-specific representation changes. We then estimate complementary merging coefficients at two granularities from the embedding space: layer-wise coefficients from coarse-grained signals and element-wise coefficients from fine-grained signals, which are jointly combined for robust coefficient estimation. Experiments on interactive effect prediction benchmarks show that our method outperforms existing merging methods and even surpasses task-specific fine-tuned models, establishing that embedding space signals provide a principled and effective foundation for cross-modal MLLM merging.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Mol-LLaMA: Towards General Understanding of Molecules in Large Molecular Language Model
Feb 19, 2025Understanding molecules is key to understanding organisms and driving advances in drug discovery, requiring interdisciplinary knowledge across chemistry and biology. Although large molecular language models have achieved notable success in interpreting molecular structures, their instruction datasets are limited to the specific knowledge from task-oriented datasets and do not fully cover the fundamental characteristics of molecules, hindering their abilities as general-purpose molecular assistants. To address this issue, we propose Mol-LLaMA, a large molecular language model that grasps the general knowledge centered on molecules via multi-modal instruction tuning. To this end, we design key data types that encompass the fundamental features of molecules, incorporating essential knowledge from molecular structures. In addition, to improve understanding of molecular features, we introduce a module that integrates complementary information from different molecular encoders, leveraging the distinct advantages of different molecular representations. Our experimental results demonstrate that Mol-LLaMA is capable of comprehending the general features of molecules and generating relevant responses to users' queries with detailed explanations, implying its potential as a general-purpose assistant for molecular analysis.
Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship
Apr 29, 2024



The goal of protein representation learning is to extract knowledge from protein databases that can be applied to various protein-related downstream tasks. Although protein sequence, structure, and function are the three key modalities for a comprehensive understanding of proteins, existing methods for protein representation learning have utilized only one or two of these modalities due to the difficulty of capturing the asymmetric interrelationships between them. To account for this asymmetry, we introduce our novel asymmetric multi-modal masked autoencoder (AMMA). AMMA adopts (1) a unified multi-modal encoder to integrate all three modalities into a unified representation space and (2) asymmetric decoders to ensure that sequence latent features reflect structural and functional information. The experiments demonstrate that the proposed AMMA is highly effective in learning protein representations that exhibit well-aligned inter-modal relationships, which in turn makes it effective for various downstream protein-related tasks.
Graph Generation with Destination-Driven Diffusion Mixture
Feb 07, 2023Generation of graphs is a major challenge for real-world tasks that require understanding the complex nature of their non-Euclidean structures. Although diffusion models have achieved notable success in graph generation recently, they are ill-suited for modeling the structural information of graphs since learning to denoise the noisy samples does not explicitly capture the graph topology. To tackle this limitation, we propose a novel generative process that models the topology of graphs by predicting the destination of the process. Specifically, we design the generative process as a mixture of diffusion processes conditioned on the endpoint in the data distribution, which drives the process toward the probable destination. Further, we introduce new training objectives for learning to predict the destination, and discuss the advantages of our generative framework that can explicitly model the graph topology and exploit the inductive bias of the data. Through extensive experimental validation on general graph and 2D/3D molecular graph generation tasks, we show that our method outperforms previous generative models, generating graphs with correct topology with both continuous and discrete features.
Graph Self-supervised Learning with Accurate Discrepancy Learning
Feb 17, 2022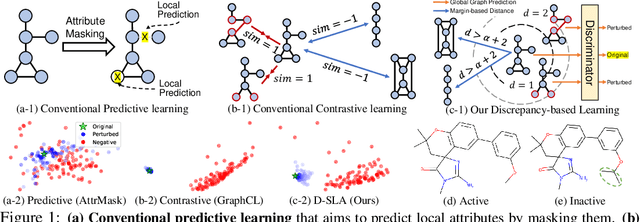


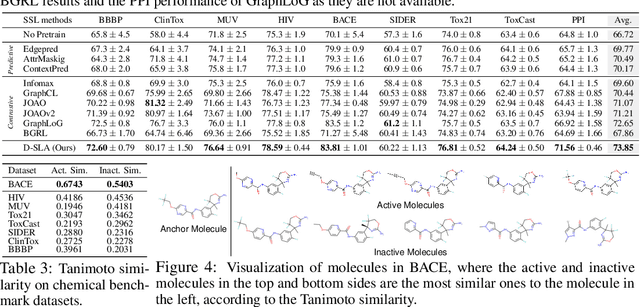
Self-supervised learning of graph neural networks (GNNs) aims to learn an accurate representation of the graphs in an unsupervised manner, to obtain transferable representations of them for diverse downstream tasks. Predictive learning and contrastive learning are the two most prevalent approaches for graph self-supervised learning. However, they have their own drawbacks. While the predictive learning methods can learn the contextual relationships between neighboring nodes and edges, they cannot learn global graph-level similarities. Contrastive learning, while it can learn global graph-level similarities, its objective to maximize the similarity between two differently perturbed graphs may result in representations that cannot discriminate two similar graphs with different properties. To tackle such limitations, we propose a framework that aims to learn the exact discrepancy between the original and the perturbed graphs, coined as Discrepancy-based Self-supervised LeArning (D-SLA). Specifically, we create multiple perturbations of the given graph with varying degrees of similarity and train the model to predict whether each graph is the original graph or a perturbed one. Moreover, we further aim to accurately capture the amount of discrepancy for each perturbed graph using the graph edit distance. We validate our method on various graph-related downstream tasks, including molecular property prediction, protein function prediction, and link prediction tasks, on which our model largely outperforms relevant baselines.
Edge Representation Learning with Hypergraphs
Jun 30, 2021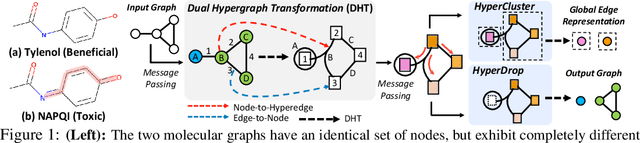

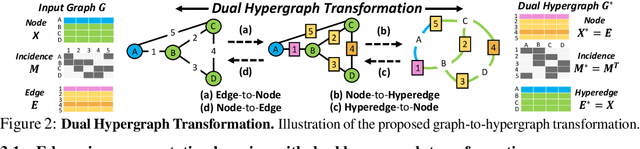
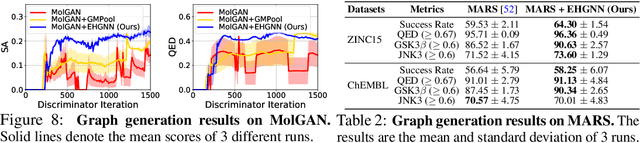
Graph neural networks have recently achieved remarkable success in representing graph-structured data, with rapid progress in both the node embedding and graph pooling methods. Yet, they mostly focus on capturing information from the nodes considering their connectivity, and not much work has been done in representing the edges, which are essential components of a graph. However, for tasks such as graph reconstruction and generation, as well as graph classification tasks for which the edges are important for discrimination, accurately representing edges of a given graph is crucial to the success of the graph representation learning. To this end, we propose a novel edge representation learning framework based on Dual Hypergraph Transformation (DHT), which transforms the edges of a graph into the nodes of a hypergraph. This dual hypergraph construction allows us to apply message passing techniques for node representations to edges. After obtaining edge representations from the hypergraphs, we then cluster or drop edges to obtain holistic graph-level edge representations. We validate our edge representation learning method with hypergraphs on diverse graph datasets for graph representation and generation performance, on which our method largely outperforms existing graph representation learning methods. Moreover, our edge representation learning and pooling method also largely outperforms state-of-the-art graph pooling methods on graph classification, not only because of its accurate edge representation learning, but also due to its lossless compression of the nodes and removal of irrelevant edges for effective message passing.