 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasily parallelizable and distributable class of algorithms for structured sparsity, with optimal acceleration
Jun 19, 2018Many statistical learning problems can be posed as minimization of a sum of two convex functions, one typically a composition of non-smooth and linear functions. Examples include regression under structured sparsity assumptions. Popular algorithms for solving such problems, e.g., ADMM, often involve non-trivial optimization subproblems or smoothing approximation. We consider two classes of primal-dual algorithms that do not incur these difficulties, and unify them from a perspective of monotone operator theory. From this unification we propose a continuum of preconditioned forward-backward operator splitting algorithms amenable to parallel and distributed computing. For the entire region of convergence of the whole continuum of algorithms, we establish its rates of convergence. For some known instances of this continuum, our analysis closes the gap in theory. We further exploit the unification to propose a continuum of accelerated algorithms. We show that the whole continuum attains the theoretically optimal rate of convergence. The scalability of the proposed algorithms, as well as their convergence behavior, is demonstrated up to 1.2 million variables with a distributed implementation.
Regression shrinkage and grouping of highly correlated predictors with HORSES
Feb 01, 2013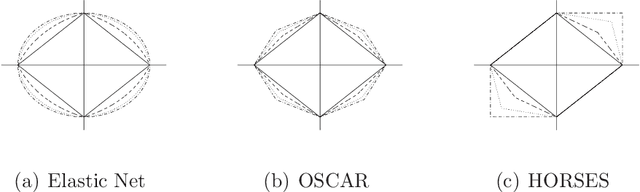



Identifying homogeneous subgroups of variables can be challenging in high dimensional data analysis with highly correlated predictors. We propose a new method called Hexagonal Operator for Regression with Shrinkage and Equality Selection, HORSES for short, that simultaneously selects positively correlated variables and identifies them as predictive clusters. This is achieved via a constrained least-squares problem with regularization that consists of a linear combination of an L_1 penalty for the coefficients and another L_1 penalty for pairwise differences of the coefficients. This specification of the penalty function encourages grouping of positively correlated predictors combined with a sparsity solution. We construct an efficient algorithm to implement the HORSES procedure. We show via simulation that the proposed method outperforms other variable selection methods in terms of prediction error and parsimony. The technique is demonstrated on two data sets, a small data set from analysis of soil in Appalachia, and a high dimensional data set from a near infrared (NIR) spectroscopy study, showing the flexibility of the methodology.