 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Cluster-Aware Self-Training for Tabular Data
Oct 10, 2023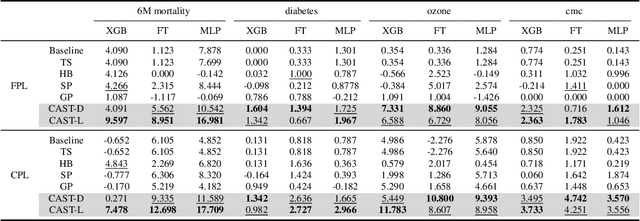
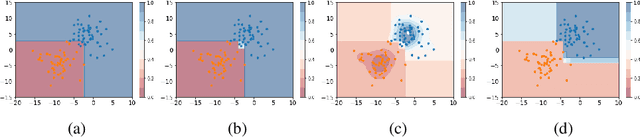
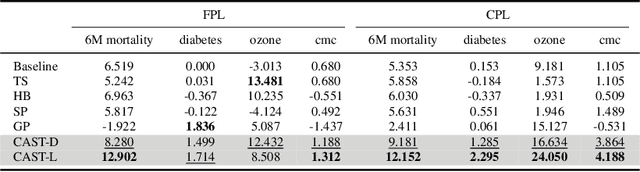
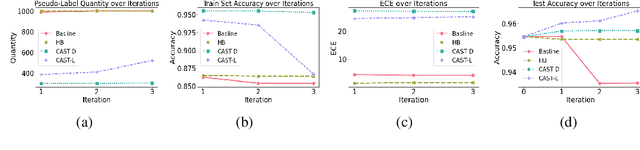
Self-training has gained attraction because of its simplicity and versatility, yet it is vulnerable to noisy pseudo-labels. Several studies have proposed successful approaches to tackle this issue, but they have diminished the advantages of self-training because they require specific modifications in self-training algorithms or model architectures. Furthermore, most of them are incompatible with gradient boosting decision trees, which dominate the tabular domain. To address this, we revisit the cluster assumption, which states that data samples that are close to each other tend to belong to the same class. Inspired by the assumption, we propose Cluster-Aware Self-Training (CAST) for tabular data. CAST is a simple and universally adaptable approach for enhancing existing self-training algorithms without significant modifications. Concretely, our method regularizes the confidence of the classifier, which represents the value of the pseudo-label, forcing the pseudo-labels in low-density regions to have lower confidence by leveraging prior knowledge for each class within the training data. Extensive empirical evaluations on up to 20 real-world datasets confirm not only the superior performance of CAST but also its robustness in various setups in self-training contexts.