 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Representations via Contrastive Learning for Instance Retrieval
Sep 28, 2022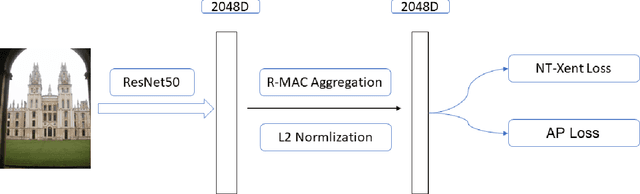
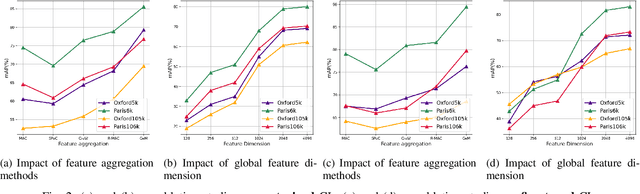


Instance-level Image Retrieval (IIR), or simply Instance Retrieval, deals with the problem of finding all the images within an dataset that contain a query instance (e.g. an object). This paper makes the first attempt that tackles this problem using instance-discrimination based contrastive learning (CL). While CL has shown impressive performance for many computer vision tasks, the similar success has never been found in the field of IIR. In this work, we approach this problem by exploring the capability of deriving discriminative representations from pre-trained and fine-tuned CL models. To begin with, we investigate the efficacy of transfer learning in IIR, by comparing off-the-shelf features learned by a pre-trained deep neural network (DNN) classifier with features learned by a CL model. The findings inspired us to propose a new training strategy that optimizes CL towards learning IIR-oriented features, by using an Average Precision (AP) loss together with a fine-tuning method to learn contrastive feature representations that are tailored to IIR. Our empirical evaluation demonstrates significant performance enhancement over the off-the-shelf features learned from a pre-trained DNN classifier on the challenging Oxford and Paris datasets.
Autonomous Control of a Line Follower Robot Using a Q-Learning Controller
Jan 23, 2020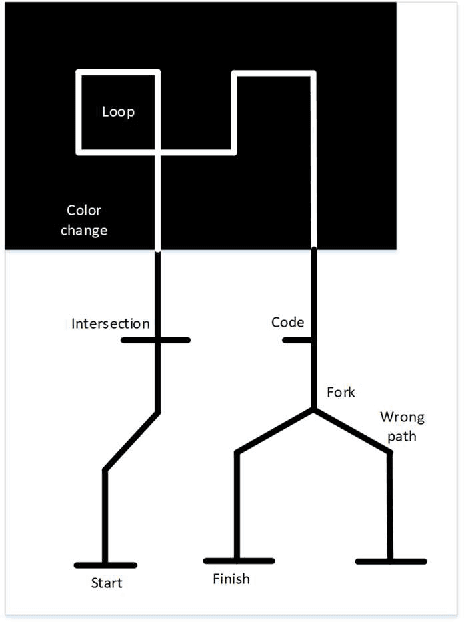

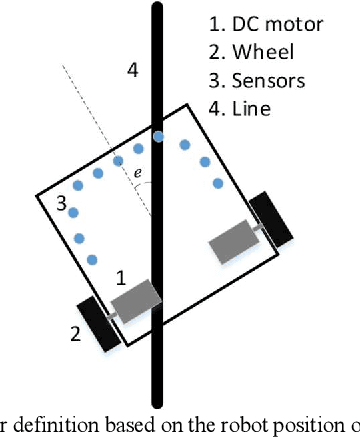
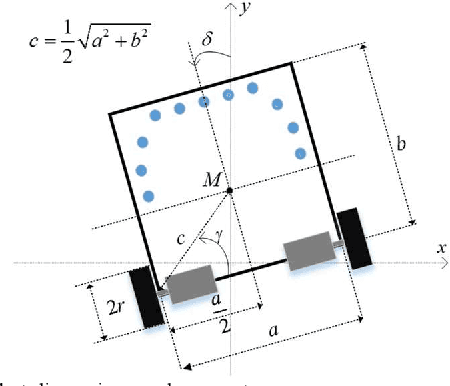
In this paper, a MIMO simulated annealing SA based Q learning method is proposed to control a line follower robot. The conventional controller for these types of robots is the proportional P controller. Considering the unknown mechanical characteristics of the robot and uncertainties such as friction and slippery surfaces, system modeling and controller designing can be extremely challenging. The mathematical modeling for the robot is presented in this paper, and a simulator is designed based on this model. The basic Q learning methods are based pure exploitation and the epsilon-greedy methods, which help exploration, can harm the controller performance after learning completion by exploring nonoptimal actions. The simulated annealing based Q learning method tackles this drawback by decreasing the exploration rate when the learning increases. The simulation and experimental results are provided to evaluate the effectiveness of the proposed controller.