 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Diversity Learning with Sample Dropout for Unsupervised Domain Adaptive Person Re-identification
Jan 25, 2022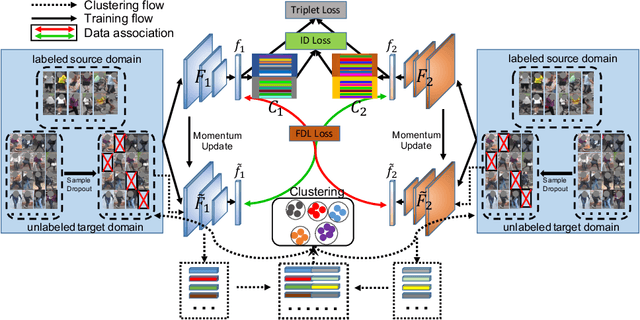
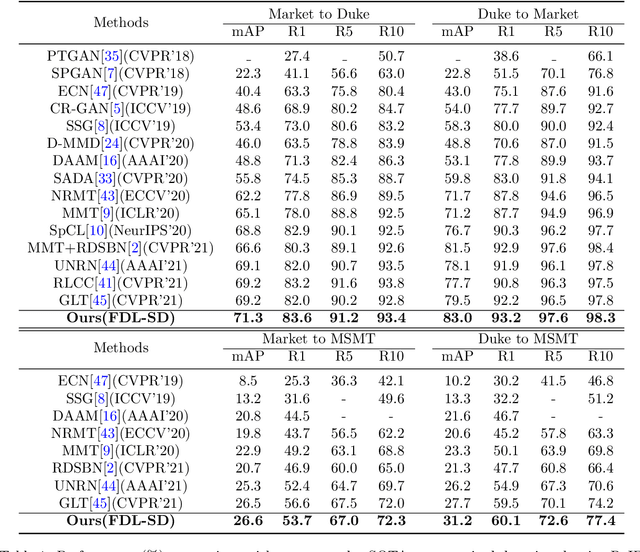


Clustering-based approach has proved effective in dealing with unsupervised domain adaptive person re-identification (ReID) tasks. However, existing works along this approach still suffer from noisy pseudo labels and the unreliable generalization ability during the whole training process. To solve these problems, this paper proposes a new approach to learn the feature representation with better generalization ability through limiting noisy pseudo labels. At first, we propose a Sample Dropout (SD) method to prevent the training of the model from falling into the vicious circle caused by samples that are frequently assigned with noisy pseudo labels. In addition, we put forward a brand-new method referred as to Feature Diversity Learning (FDL) under the classic mutual-teaching architecture, which can significantly improve the generalization ability of the feature representation on the target domain. Experimental results show that our proposed FDL-SD achieves the state-of-the-art performance on multiple benchmark datasets.
Real-time Segmentation and Facial Skin Tones Grading
Jan 09, 2020
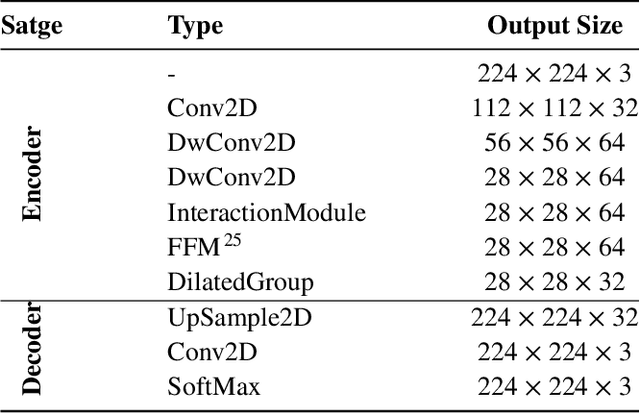
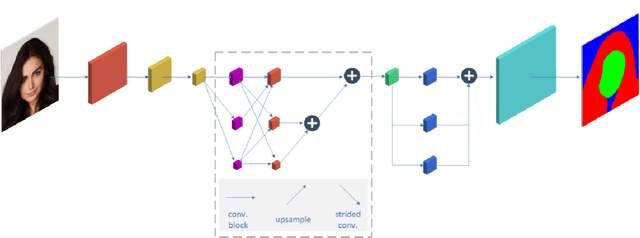
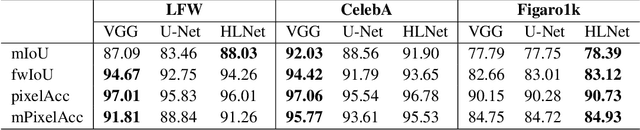
Modern approaches for semantic segmention usually pay too much attention to the accuracy of the model, and therefore it is strongly recommended to introduce cumbersome backbones, which brings heavy computation burden and memory footprint. To alleviate this problem, we propose an efficient segmentation method based on deep convolutional neural networks (DCNNs) for the task of hair and facial skin segmentation, which achieving remarkable trade-off between speed and performance on three benchmark datasets. As far as we know, the accuracy of skin tones classification is usually unsatisfactory due to the influence of external environmental factors such as illumination and background noise. Therefore, we use the segmentated face to obtain a specific face area, and further exploit the color moment algorithm to extract its color features. Specifically, for a 224 x 224 standard input, using our high-resolution spatial detail information and low-resolution contextual information fusion network (HLNet), we achieve 90.73% Pixel Accuracy on Figaro1k dataset at over 16 FPS in the case of CPU environment. Additional experiments on CamVid dataset further confirm the universality of the proposed model. We further use masked color moment for skin tones grade evaluation and approximate 80% classification accuracy demonstrate the feasibility of the proposed scheme.Code is available at https://github.com/JACKYLUO1991/Face-skin-hair-segmentaiton-and-skin-color-evaluation.
HybridNetSeg: A Compact Hybrid Network for Retinal Vessel Segmentation
Nov 22, 2019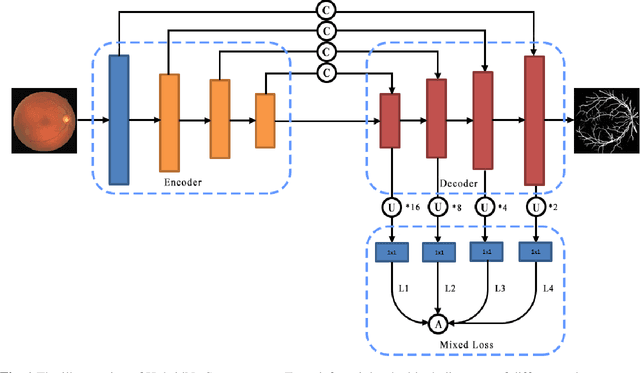
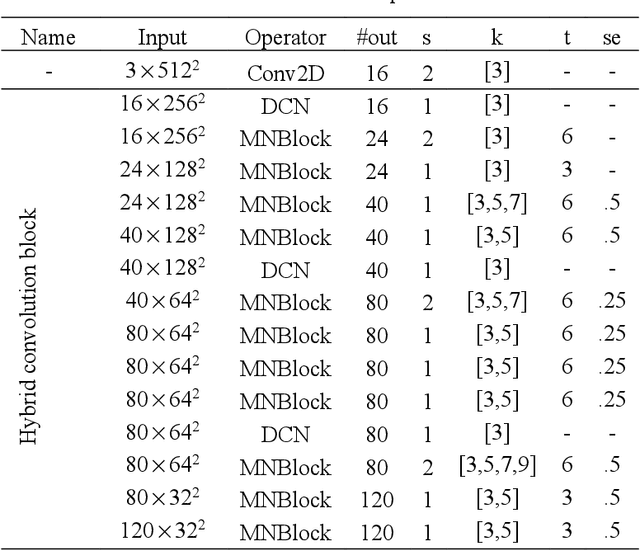
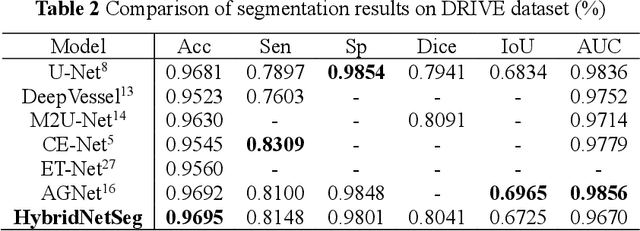
A large number of retinal vessel analysis methods based on image segmentation have emerged in recent years. However, existing methods depend on cumbersome backbones, such as VGG16 and ResNet-50, benefiting from their powerful feature extraction capabilities but suffering from high computational costs. In this paper, we propose a novel neural network (HybridNetSeg) dedicated to solving this drawback while further improving overall performance. Considering deformable convolution can extract complex and variable structural information, and larger kernel in mixed depthwise convolution makes contribution to higher accuracy. We have integrated these two modules and propose a Hybrid Convolution Block (HCB) using the idea of heuristic learning. Inspired by the U-Net, we use HCB to replace a part of the common convolution of the U-Net encoder, drastically reducing the parameter count to 0.71M while accelerating the inference process. Not only that, we also propose a multi-scale mixed loss mechanism. Extensive experiments on three major benchmark datasets demonstrate the effectiveness of our proposed method