 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Building Myopic MPC Policies using Supervised Learning
Jan 23, 2024



The application of supervised learning techniques in combination with model predictive control (MPC) has recently generated significant interest, particularly in the area of approximate explicit MPC, where function approximators like deep neural networks are used to learn the MPC policy via optimal state-action pairs generated offline. While the aim of approximate explicit MPC is to closely replicate the MPC policy, substituting online optimization with a trained neural network, the performance guarantees that come with solving the online optimization problem are typically lost. This paper considers an alternative strategy, where supervised learning is used to learn the optimal value function offline instead of learning the optimal policy. This can then be used as the cost-to-go function in a myopic MPC with a very short prediction horizon, such that the online computation burden reduces significantly without affecting the controller performance. This approach differs from existing work on value function approximations in the sense that it learns the cost-to-go function by using offline-collected state-value pairs, rather than closed-loop performance data. The cost of generating the state-value pairs used for training is addressed using a sensitivity-based data augmentation scheme.
A Bayesian optimization framework for the automatic tuning of MPC-based shared controllers
Nov 02, 2023
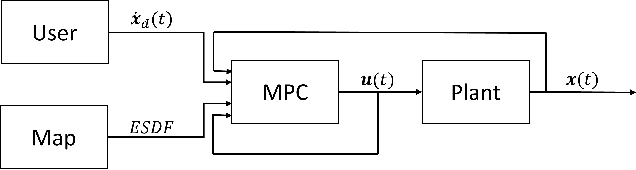

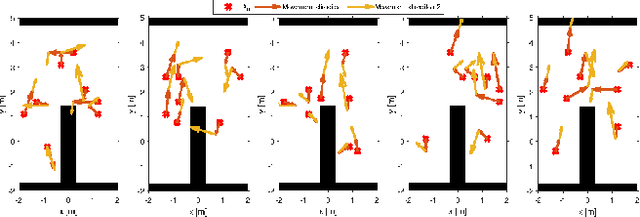
This paper presents a Bayesian optimization framework for the automatic tuning of shared controllers which are defined as a Model Predictive Control (MPC) problem. The proposed framework includes the design of performance metrics as well as the representation of user inputs for simulation-based optimization. The framework is applied to the optimization of a shared controller for an Image Guided Therapy robot. VR-based user experiments confirm the increase in performance of the automatically tuned MPC shared controller with respect to a hand-tuned baseline version as well as its generalization ability.
An Improved Data Augmentation Scheme for Model Predictive Control Policy Approximation
Mar 09, 2023This paper considers the problem of data generation for MPC policy approximation. Learning an approximate MPC policy from expert demonstrations requires a large data set consisting of optimal state-action pairs, sampled across the feasible state space. Yet, the key challenge of efficiently generating the training samples has not been studied widely. Recently, a sensitivity-based data augmentation framework for MPC policy approximation was proposed, where the parametric sensitivities are exploited to cheaply generate several additional samples from a single offline MPC computation. The error due to augmenting the training data set with inexact samples was shown to increase with the size of the neighborhood around each sample used for data augmentation. Building upon this work, this letter paper presents an improved data augmentation scheme based on predictor-corrector steps that enforces a user-defined level of accuracy, and shows that the error bound of the augmented samples are independent of the size of the neighborhood used for data augmentation.