 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Predictive Coding: A Unified Neural Framework for Learning Hierarchical World Models for Perception and Planning
Oct 23, 2022
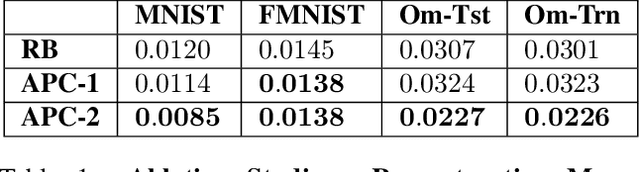
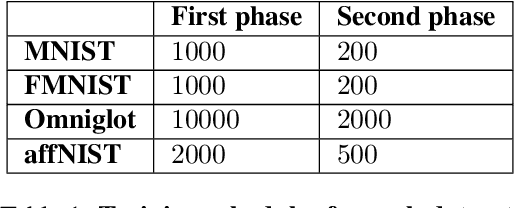
Predictive coding has emerged as a prominent model of how the brain learns through predictions, anticipating the importance accorded to predictive learning in recent AI architectures such as transformers. Here we propose a new framework for predictive coding called active predictive coding which can learn hierarchical world models and solve two radically different open problems in AI: (1) how do we learn compositional representations, e.g., part-whole hierarchies, for equivariant vision? and (2) how do we solve large-scale planning problems, which are hard for traditional reinforcement learning, by composing complex action sequences from primitive policies? Our approach exploits hypernetworks, self-supervised learning and reinforcement learning to learn hierarchical world models that combine task-invariant state transition networks and task-dependent policy networks at multiple abstraction levels. We demonstrate the viability of our approach on a variety of vision datasets (MNIST, FashionMNIST, Omniglot) as well as on a scalable hierarchical planning problem. Our results represent, to our knowledge, the first demonstration of a unified solution to the part-whole learning problem posed by Hinton, the nested reference frames problem posed by Hawkins, and the integrated state-action hierarchy learning problem in reinforcement learning.
Hyper-Universal Policy Approximation: Learning to Generate Actions from a Single Image using Hypernets
Jul 07, 2022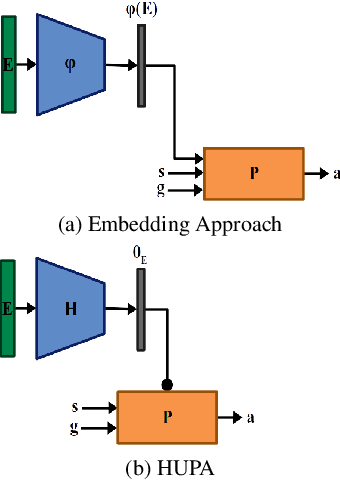
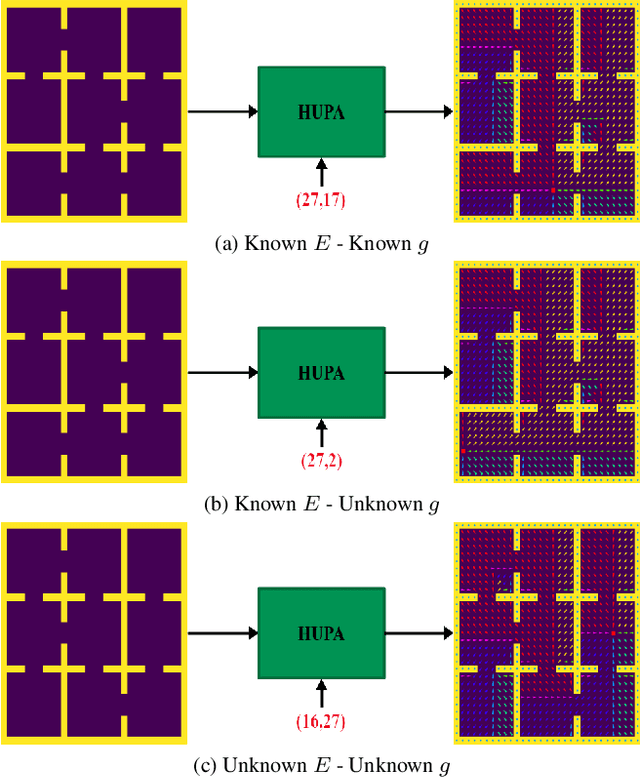
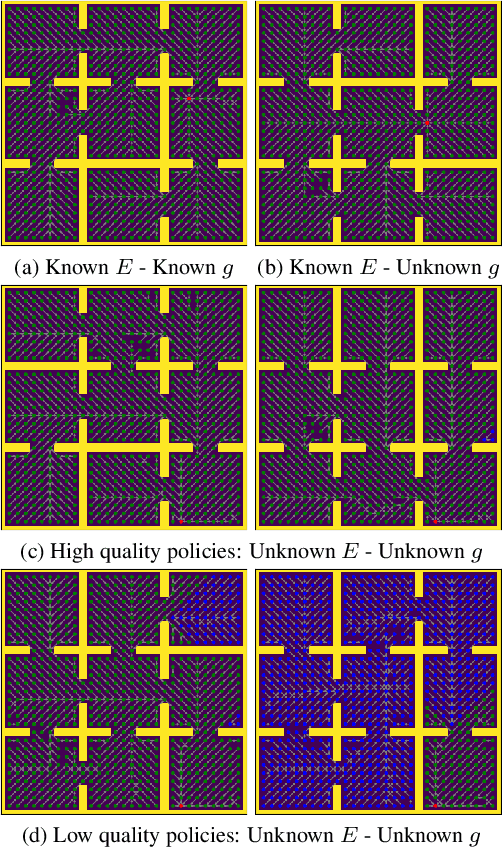
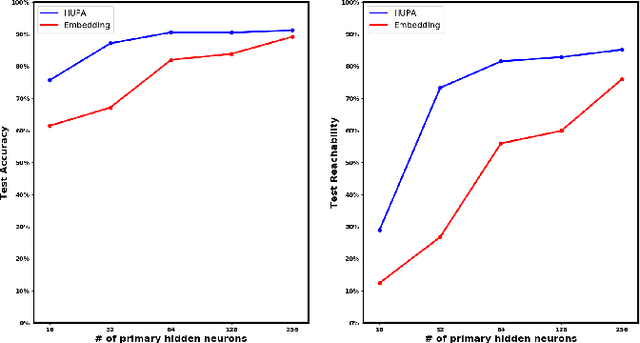
Inspired by Gibson's notion of object affordances in human vision, we ask the question: how can an agent learn to predict an entire action policy for a novel object or environment given only a single glimpse? To tackle this problem, we introduce the concept of Universal Policy Functions (UPFs) which are state-to-action mappings that generalize not only to new goals but most importantly to novel, unseen environments. Specifically, we consider the problem of efficiently learning such policies for agents with limited computational and communication capacity, constraints that are frequently encountered in edge devices. We propose the Hyper-Universal Policy Approximator (HUPA), a hypernetwork-based model to generate small task- and environment-conditional policy networks from a single image, with good generalization properties. Our results show that HUPAs significantly outperform an embedding-based alternative for generated policies that are size-constrained. Although this work is restricted to a simple map-based navigation task, future work includes applying the principles behind HUPAs to learning more general affordances for objects and environments.
Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies
Jan 14, 2022We introduce Active Predictive Coding Networks (APCNs), a new class of neural networks that solve a major problem posed by Hinton and others in the fields of artificial intelligence and brain modeling: how can neural networks learn intrinsic reference frames for objects and parse visual scenes into part-whole hierarchies by dynamically allocating nodes in a parse tree? APCNs address this problem by using a novel combination of ideas: (1) hypernetworks are used for dynamically generating recurrent neural networks that predict parts and their locations within intrinsic reference frames conditioned on higher object-level embedding vectors, and (2) reinforcement learning is used in conjunction with backpropagation for end-to-end learning of model parameters. The APCN architecture lends itself naturally to multi-level hierarchical learning and is closely related to predictive coding models of cortical function. Using the MNIST, Fashion-MNIST and Omniglot datasets, we demonstrate that APCNs can (a) learn to parse images into part-whole hierarchies, (b) learn compositional representations, and (c) transfer their knowledge to unseen classes of objects. With their ability to dynamically generate parse trees with part locations for objects, APCNs offer a new framework for explainable AI that leverages advances in deep learning while retaining interpretability and compositionality.
Transformational Sparse Coding
Dec 08, 2017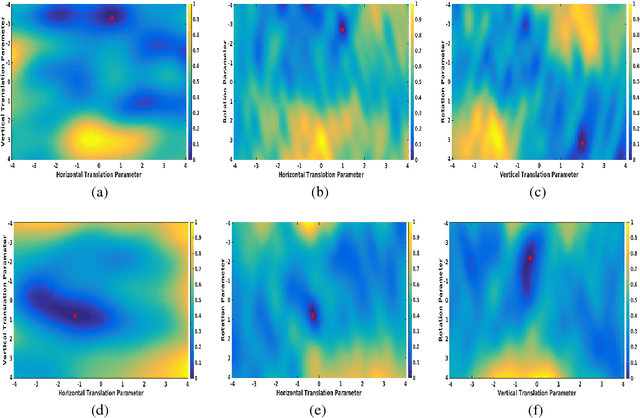

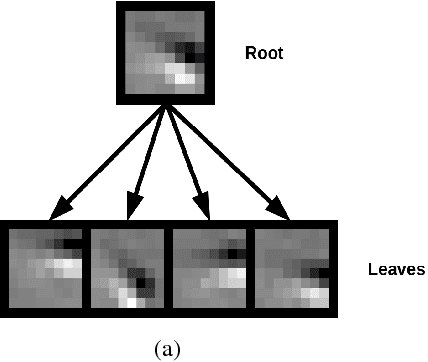
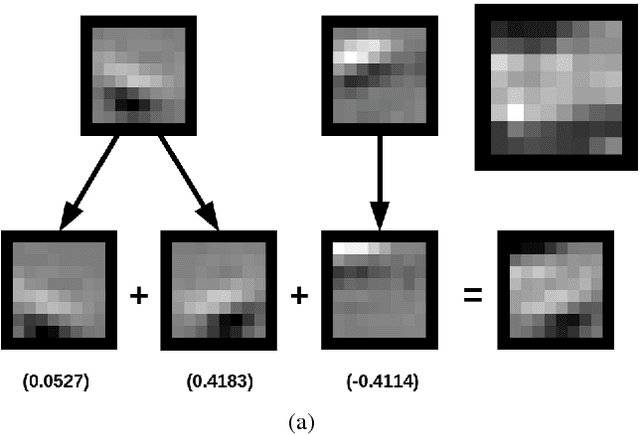
A fundamental problem faced by object recognition systems is that objects and their features can appear in different locations, scales and orientations. Current deep learning methods attempt to achieve invariance to local translations via pooling, discarding the locations of features in the process. Other approaches explicitly learn transformed versions of the same feature, leading to representations that quickly explode in size. Instead of discarding the rich and useful information about feature transformations to achieve invariance, we argue that models should learn object features conjointly with their transformations to achieve equivariance. We propose a new model of unsupervised learning based on sparse coding that can learn object features jointly with their affine transformations directly from images. Results based on learning from natural images indicate that our approach matches the reconstruction quality of traditional sparse coding but with significantly fewer degrees of freedom while simultaneously learning transformations from data. These results open the door to scaling up unsupervised learning to allow deep feature+transformation learning in a manner consistent with the ventral+dorsal stream architecture of the primate visual cortex.