 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Universal Policy Approximation: Learning to Generate Actions from a Single Image using Hypernets
Paper and Code
Jul 07, 2022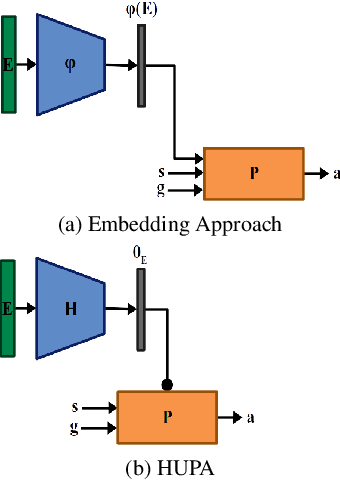
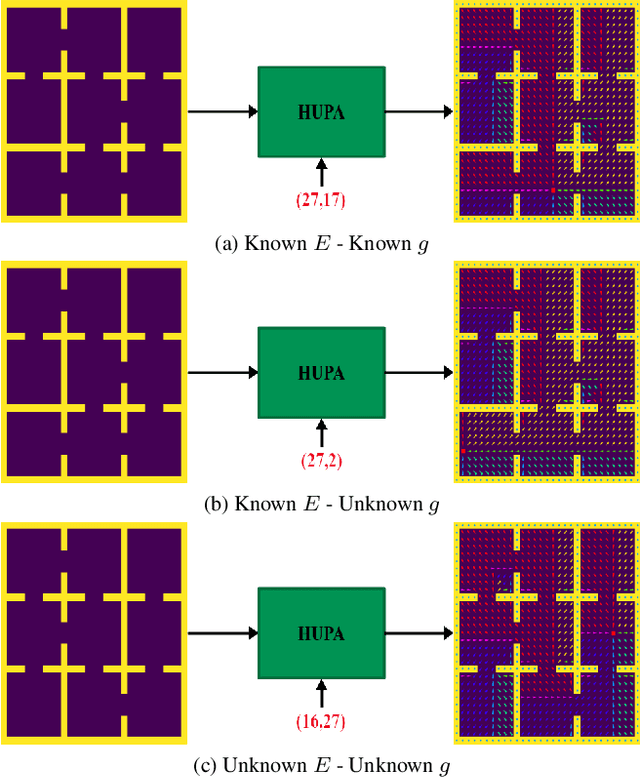
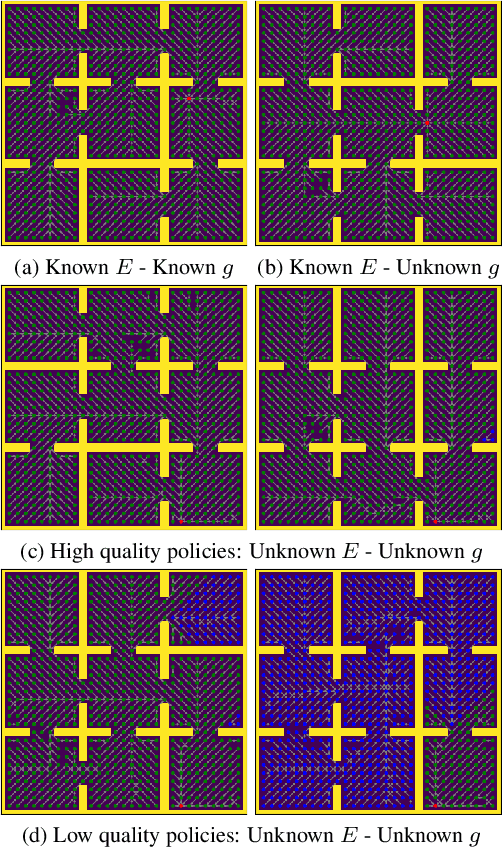
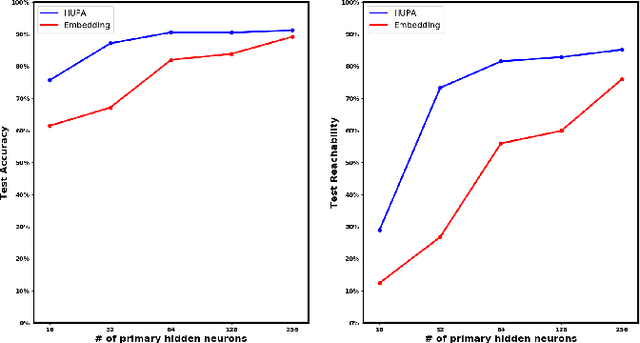
Inspired by Gibson's notion of object affordances in human vision, we ask the question: how can an agent learn to predict an entire action policy for a novel object or environment given only a single glimpse? To tackle this problem, we introduce the concept of Universal Policy Functions (UPFs) which are state-to-action mappings that generalize not only to new goals but most importantly to novel, unseen environments. Specifically, we consider the problem of efficiently learning such policies for agents with limited computational and communication capacity, constraints that are frequently encountered in edge devices. We propose the Hyper-Universal Policy Approximator (HUPA), a hypernetwork-based model to generate small task- and environment-conditional policy networks from a single image, with good generalization properties. Our results show that HUPAs significantly outperform an embedding-based alternative for generated policies that are size-constrained. Although this work is restricted to a simple map-based navigation task, future work includes applying the principles behind HUPAs to learning more general affordances for objects and environments.