 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformational Sparse Coding
Paper and Code
Dec 08, 2017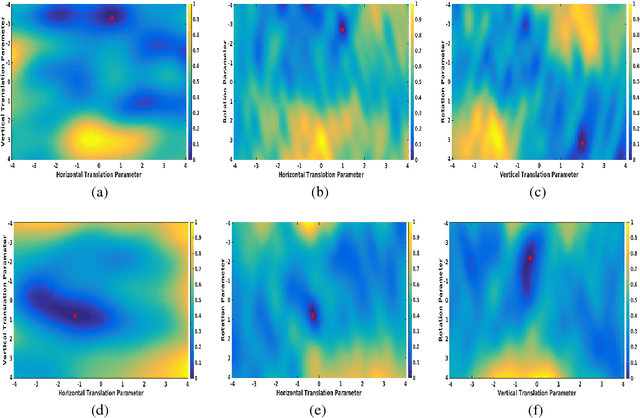

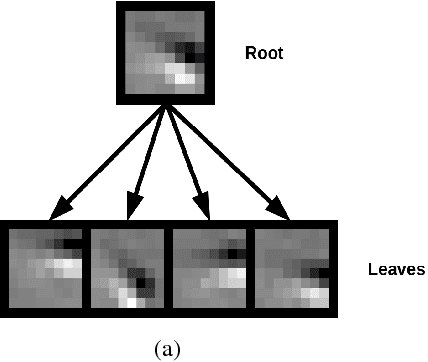
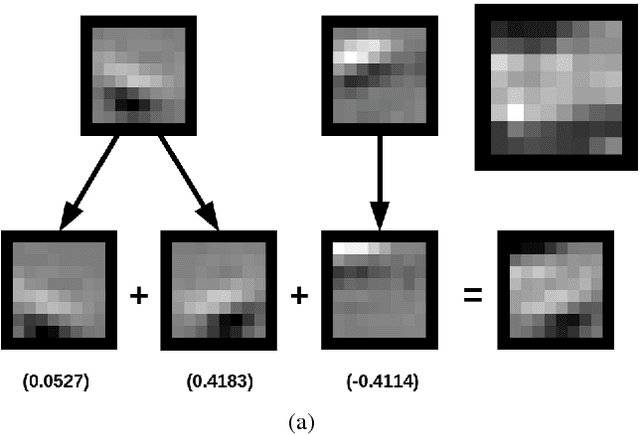
A fundamental problem faced by object recognition systems is that objects and their features can appear in different locations, scales and orientations. Current deep learning methods attempt to achieve invariance to local translations via pooling, discarding the locations of features in the process. Other approaches explicitly learn transformed versions of the same feature, leading to representations that quickly explode in size. Instead of discarding the rich and useful information about feature transformations to achieve invariance, we argue that models should learn object features conjointly with their transformations to achieve equivariance. We propose a new model of unsupervised learning based on sparse coding that can learn object features jointly with their affine transformations directly from images. Results based on learning from natural images indicate that our approach matches the reconstruction quality of traditional sparse coding but with significantly fewer degrees of freedom while simultaneously learning transformations from data. These results open the door to scaling up unsupervised learning to allow deep feature+transformation learning in a manner consistent with the ventral+dorsal stream architecture of the primate visual cortex.