 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI_INFN Platform: Artificial Intelligence Development in the Cloud
Sep 26, 2025Machine Learning (ML) is driving a revolution in the way scientists design, develop, and deploy data-intensive software. However, the adoption of ML presents new challenges for the computing infrastructure, particularly in terms of provisioning and orchestrating access to hardware accelerators for development, testing, and production. The INFN-funded project AI_INFN (Artificial Intelligence at INFN) aims at fostering the adoption of ML techniques within INFN use cases by providing support on multiple aspects, including the provisioning of AI-tailored computing resources. It leverages cloud-native solutions in the context of INFN Cloud, to share hardware accelerators as effectively as possible, ensuring the diversity of the Institute's research activities is not compromised. In this contribution, we provide an update on the commissioning of a Kubernetes platform designed to ease the development of GPU-powered data analysis workflows and their scalability on heterogeneous distributed computing resources, also using the offloading mechanism with Virtual Kubelet and InterLink API. This setup can manage workflows across different resource providers, including sites of the Worldwide LHC Computing Grid and supercomputers such as CINECA Leonardo, providing a model for use cases requiring dedicated infrastructures for different parts of the workload. Initial test results, emerging case studies, and integration scenarios will be presented with functional tests and benchmarks.
Supporting the development of Machine Learning for fundamental science in a federated Cloud with the AI_INFN platform
Feb 28, 2025

Machine Learning (ML) is driving a revolution in the way scientists design, develop, and deploy data-intensive software. However, the adoption of ML presents new challenges for the computing infrastructure, particularly in terms of provisioning and orchestrating access to hardware accelerators for development, testing, and production. The INFN-funded project AI_INFN ("Artificial Intelligence at INFN") aims at fostering the adoption of ML techniques within INFN use cases by providing support on multiple aspects, including the provision of AI-tailored computing resources. It leverages cloud-native solutions in the context of INFN Cloud, to share hardware accelerators as effectively as possible, ensuring the diversity of the Institute's research activities is not compromised. In this contribution, we provide an update on the commissioning of a Kubernetes platform designed to ease the development of GPU-powered data analysis workflows and their scalability on heterogeneous, distributed computing resources, possibly federated as Virtual Kubelets with the interLink provider.
Collection and harmonization of system logs and prototypal Analytics services with the Elastic (ELK) suite at the INFN-CNAF computing centre
May 13, 2021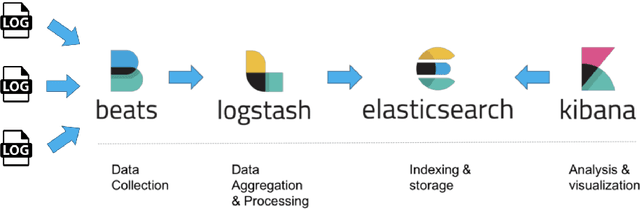
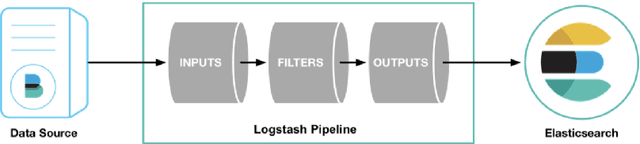
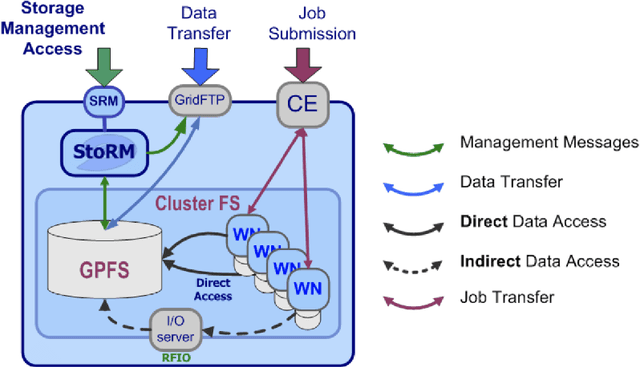
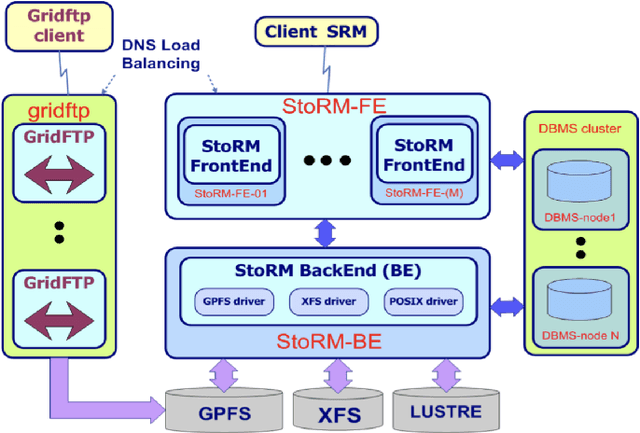
The distributed Grid infrastructure for High Energy Physics experiments at the Large Hadron Collider (LHC) in Geneva comprises a set of computing centres, spread all over the world, as part of the Worldwide LHC Computing Grid (WLCG). In Italy, the Tier-1 functionalities are served by the INFN-CNAF data center, which provides also computing and storage resources to more than twenty non-LHC experiments. For this reason, a high amount of logs are collected each day from various sources, which are highly heterogeneous and difficult to harmonize. In this contribution, a working implementation of a system that collects, parses and displays the log information from CNAF data sources and the investigation of a Machine Learning based predictive maintenance system, is presented.
* Submitted to proceedings of International Symposium on Grids & Clouds 2019 (ISGC2019)