 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Disease Differential Diagnosis with Large Language Models at Scale: From Abdominal Actinomycosis to Wilson's Disease
Feb 20, 2025



Large language models (LLMs) have demonstrated impressive capabilities in disease diagnosis. However, their effectiveness in identifying rarer diseases, which are inherently more challenging to diagnose, remains an open question. Rare disease performance is critical with the increasing use of LLMs in healthcare settings. This is especially true if a primary care physician needs to make a rarer prognosis from only a patient conversation so that they can take the appropriate next step. To that end, several clinical decision support systems are designed to support providers in rare disease identification. Yet their utility is limited due to their lack of knowledge of common disorders and difficulty of use. In this paper, we propose RareScale to combine the knowledge LLMs with expert systems. We use jointly use an expert system and LLM to simulate rare disease chats. This data is used to train a rare disease candidate predictor model. Candidates from this smaller model are then used as additional inputs to black-box LLM to make the final differential diagnosis. Thus, RareScale allows for a balance between rare and common diagnoses. We present results on over 575 rare diseases, beginning with Abdominal Actinomycosis and ending with Wilson's Disease. Our approach significantly improves the baseline performance of black-box LLMs by over 17% in Top-5 accuracy. We also find that our candidate generation performance is high (e.g. 88.8% on gpt-4o generated chats).
How well do you know your summarization datasets?
Jun 21, 2021
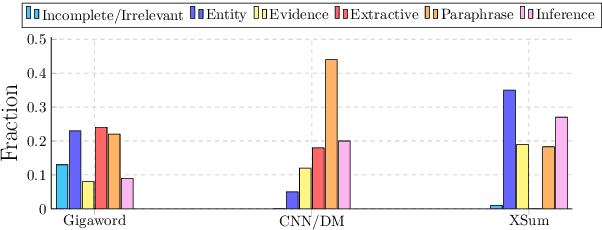


State-of-the-art summarization systems are trained and evaluated on massive datasets scraped from the web. Despite their prevalence, we know very little about the underlying characteristics (data noise, summarization complexity, etc.) of these datasets, and how these affect system performance and the reliability of automatic metrics like ROUGE. In this study, we manually analyze 600 samples from three popular summarization datasets. Our study is driven by a six-class typology which captures different noise types (missing facts, entities) and degrees of summarization difficulty (extractive, abstractive). We follow with a thorough analysis of 27 state-of-the-art summarization models and 5 popular metrics, and report our key insights: (1) Datasets have distinct data quality and complexity distributions, which can be traced back to their collection process. (2) The performance of models and reliability of metrics is dependent on sample complexity. (3) Faithful summaries often receive low scores because of the poor diversity of references. We release the code, annotated data and model outputs.