 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective and Subjective Evaluation of Diffusion-Based Speech Enhancement for Dysarthric Speech
Aug 25, 2025Dysarthric speech poses significant challenges for automatic speech recognition (ASR) systems due to its high variability and reduced intelligibility. In this work we explore the use of diffusion models for dysarthric speech enhancement, which is based on the hypothesis that using diffusion-based speech enhancement moves the distribution of dysarthric speech closer to that of typical speech, which could potentially improve dysarthric speech recognition performance. We assess the effect of two diffusion-based and one signal-processing-based speech enhancement algorithms on intelligibility and speech quality of two English dysarthric speech corpora. We applied speech enhancement to both typical and dysarthric speech and evaluate the ASR performance using Whisper-Turbo, and the subjective and objective speech quality of the original and enhanced dysarthric speech. We also fine-tuned Whisper-Turbo on the enhanced speech to assess its impact on recognition performance.
Faster Q-Learning Algorithms for Restless Bandits
Sep 06, 2024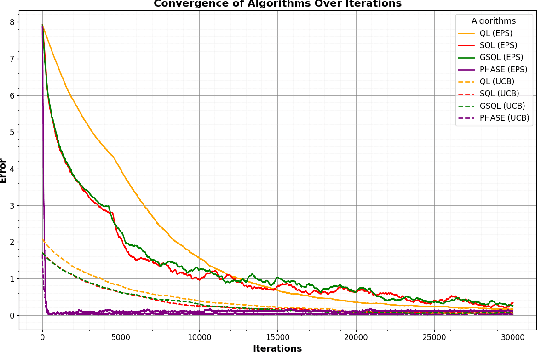


We study the Whittle index learning algorithm for restless multi-armed bandits (RMAB). We first present Q-learning algorithm and its variants -- speedy Q-learning (SQL), generalized speedy Q-learning (GSQL) and phase Q-learning (PhaseQL). We also discuss exploration policies -- $\epsilon$-greedy and Upper confidence bound (UCB). We extend the study of Q-learning and its variants with UCB policy. We illustrate using numerical example that Q-learning with UCB exploration policy has faster convergence and PhaseQL with UCB have fastest convergence rate. We next extend the study of Q-learning variants for index learning to RMAB. The algorithm of index learning is two-timescale variant of stochastic approximation, on slower timescale we update index learning scheme and on faster timescale we update Q-learning assuming fixed index value. We study constant stepsizes two timescale stochastic approximation algorithm. We describe the performance of our algorithms using numerical example. It illustrate that index learning with Q learning with UCB has faster convergence that $\epsilon$ greedy. Further, PhaseQL (with UCB and $\epsilon$ greedy) has the best convergence than other Q-learning algorithms.