 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Deterministic Multi-Agent Reinforcement Learning
Feb 19, 2021

[Zhang, ICML 2018] provided the first decentralized actor-critic algorithm for multi-agent reinforcement learning (MARL) that offers convergence guarantees. In that work, policies are stochastic and are defined on finite action spaces. We extend those results to offer a provably-convergent decentralized actor-critic algorithm for learning deterministic policies on continuous action spaces. Deterministic policies are important in real-world settings. To handle the lack of exploration inherent in deterministic policies, we consider both off-policy and on-policy settings. We provide the expression of a local deterministic policy gradient, decentralized deterministic actor-critic algorithms and convergence guarantees for linearly-approximated value functions. This work will help enable decentralized MARL in high-dimensional action spaces and pave the way for more widespread use of MARL.
Efficient Reinforcement Learning in Resource Allocation Problems Through Permutation Invariant Multi-task Learning
Feb 18, 2021


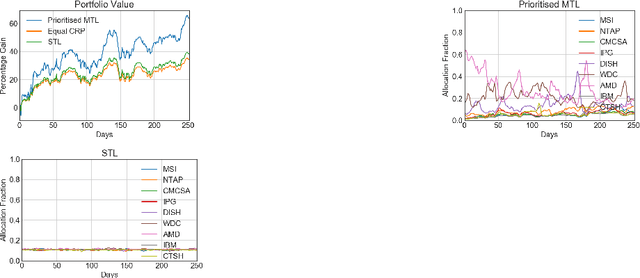
One of the main challenges in real-world reinforcement learning is to learn successfully from limited training samples. We show that in certain settings, the available data can be dramatically increased through a form of multi-task learning, by exploiting an invariance property in the tasks. We provide a theoretical performance bound for the gain in sample efficiency under this setting. This motivates a new approach to multi-task learning, which involves the design of an appropriate neural network architecture and a prioritized task-sampling strategy. We demonstrate empirically the effectiveness of the proposed approach on two real-world sequential resource allocation tasks where this invariance property occurs: financial portfolio optimization and meta federated learning.
Probabilistic Inference for Learning from Untrusted Sources
Jan 15, 2021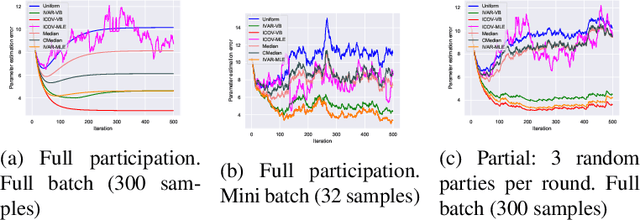
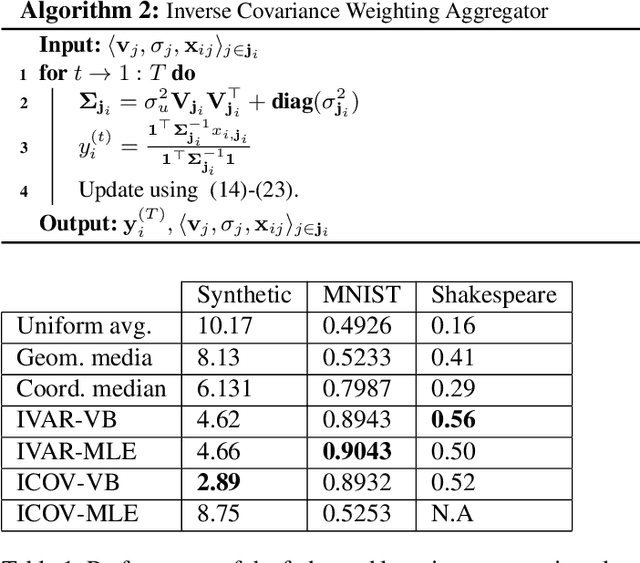
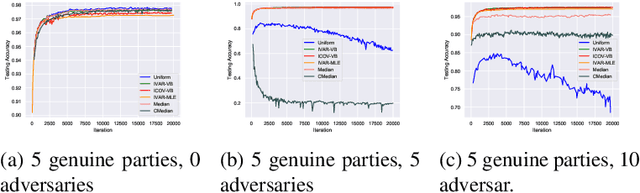
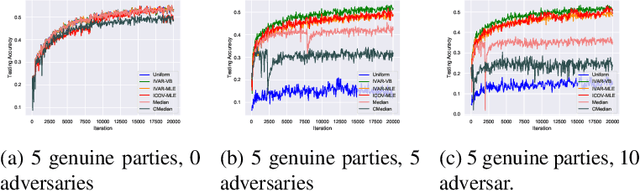
Federated learning brings potential benefits of faster learning, better solutions, and a greater propensity to transfer when heterogeneous data from different parties increases diversity. However, because federated learning tasks tend to be large and complex, and training times non-negligible, it is important for the aggregation algorithm to be robust to non-IID data and corrupted parties. This robustness relies on the ability to identify, and appropriately weight, incompatible parties. Recent work assumes that a \textit{reference dataset} is available through which to perform the identification. We consider settings where no such reference dataset is available; rather, the quality and suitability of the parties needs to be \textit{inferred}. We do so by bringing ideas from crowdsourced predictions and collaborative filtering, where one must infer an unknown ground truth given proposals from participants with unknown quality. We propose novel federated learning aggregation algorithms based on Bayesian inference that adapt to the quality of the parties. Empirically, we show that the algorithms outperform standard and robust aggregation in federated learning on both synthetic and real data.
Variational Bayesian Inference for Crowdsourcing Predictions
Jun 02, 2020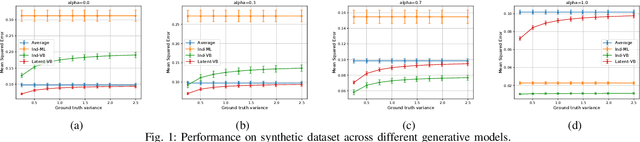
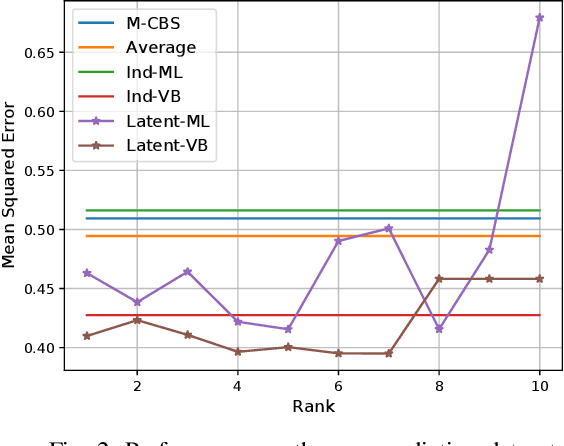
Crowdsourcing has emerged as an effective means for performing a number of machine learning tasks such as annotation and labelling of images and other data sets. In most early settings of crowdsourcing, the task involved classification, that is assigning one of a discrete set of labels to each task. Recently, however, more complex tasks have been attempted including asking crowdsource workers to assign continuous labels, or predictions. In essence, this involves the use of crowdsourcing for function estimation. We are motivated by this problem to drive applications such as collaborative prediction, that is, harnessing the wisdom of the crowd to predict quantities more accurately. To do so, we propose a Bayesian approach aimed specifically at alleviating overfitting, a typical impediment to accurate prediction models in practice. In particular, we develop a variational Bayesian technique for two different worker noise models - one that assumes workers' noises are independent and the other that assumes workers' noises have a latent low-rank structure. Our evaluations on synthetic and real-world datasets demonstrate that these Bayesian approaches perform significantly better than existing non-Bayesian approaches and are thus potentially useful for this class of crowdsourcing problems.