 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Inference for Learning from Untrusted Sources
Paper and Code
Jan 15, 2021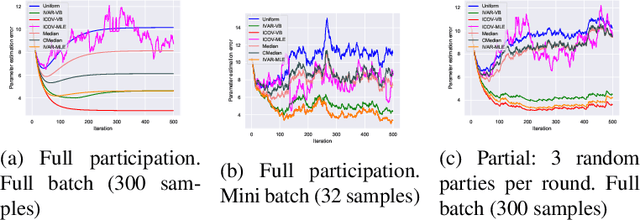
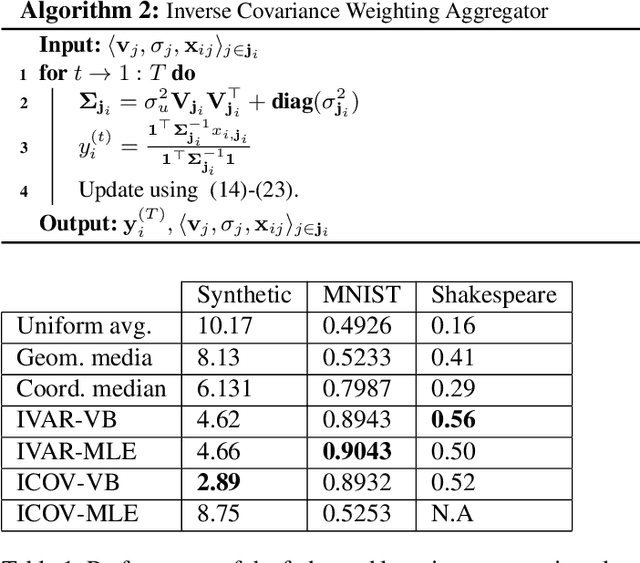
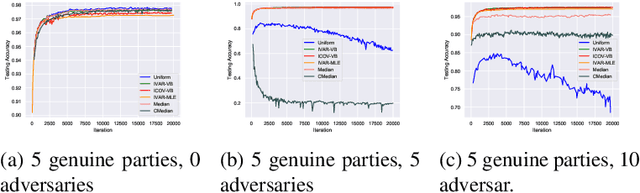
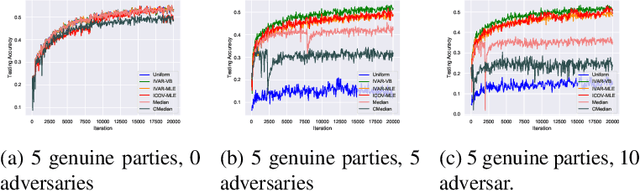
Federated learning brings potential benefits of faster learning, better solutions, and a greater propensity to transfer when heterogeneous data from different parties increases diversity. However, because federated learning tasks tend to be large and complex, and training times non-negligible, it is important for the aggregation algorithm to be robust to non-IID data and corrupted parties. This robustness relies on the ability to identify, and appropriately weight, incompatible parties. Recent work assumes that a \textit{reference dataset} is available through which to perform the identification. We consider settings where no such reference dataset is available; rather, the quality and suitability of the parties needs to be \textit{inferred}. We do so by bringing ideas from crowdsourced predictions and collaborative filtering, where one must infer an unknown ground truth given proposals from participants with unknown quality. We propose novel federated learning aggregation algorithms based on Bayesian inference that adapt to the quality of the parties. Empirically, we show that the algorithms outperform standard and robust aggregation in federated learning on both synthetic and real data.