 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid deep learning-based strategy for the hepatocellular carcinoma cancer grade classification of H&E stained liver histopathology images
Dec 04, 2024



Hepatocellular carcinoma (HCC) is a common type of liver cancer whose early-stage diagnosis is a common challenge, mainly due to the manual assessment of hematoxylin and eosin-stained whole slide images, which is a time-consuming process and may lead to variability in decision-making. For accurate detection of HCC, we propose a hybrid deep learning-based architecture that uses transfer learning to extract the features from pre-trained convolutional neural network (CNN) models and a classifier made up of a sequence of fully connected layers. This study uses a publicly available The Cancer Genome Atlas Hepatocellular Carcinoma (TCGA-LIHC)database (n=491) for model development and database of Kasturba Gandhi Medical College (KMC), India for validation. The pre-processing step involves patch extraction, colour normalization, and augmentation that results in 3920 patches for the TCGA dataset. The developed hybrid deep neural network consisting of a CNN-based pre-trained feature extractor and a customized artificial neural network-based classifier is trained using five-fold cross-validation. For this study, eight different state-of-the-art models are trained and tested as feature extractors for the proposed hybrid model. The proposed hybrid model with ResNet50-based feature extractor provided the sensitivity, specificity, F1-score, accuracy, and AUC of 100.00%, 100.00%, 100.00%, 100.00%, and 1.00, respectively on the TCGA database. On the KMC database, EfficientNetb3 resulted in the optimal choice of the feature extractor giving sensitivity, specificity, F1-score, accuracy, and AUC of 96.97, 98.85, 96.71, 96.71, and 0.99, respectively. The proposed hybrid models showed improvement in accuracy of 2% and 4% over the pre-trained models in TCGA-LIHC and KMC databases.
A New Multimodal Medical Image Fusion based on Laplacian Autoencoder with Channel Attention
Oct 18, 2023



Medical image fusion combines the complementary information of multimodal medical images to assist medical professionals in the clinical diagnosis of patients' disorders and provide guidance during preoperative and intra-operative procedures. Deep learning (DL) models have achieved end-to-end image fusion with highly robust and accurate fusion performance. However, most DL-based fusion models perform down-sampling on the input images to minimize the number of learnable parameters and computations. During this process, salient features of the source images become irretrievable leading to the loss of crucial diagnostic edge details and contrast of various brain tissues. In this paper, we propose a new multimodal medical image fusion model is proposed that is based on integrated Laplacian-Gaussian concatenation with attention pooling (LGCA). We prove that our model preserves effectively complementary information and important tissue structures.
Multi-modal Medical Neurological Image Fusion using Wavelet Pooled Edge Preserving Autoencoder
Oct 18, 2023
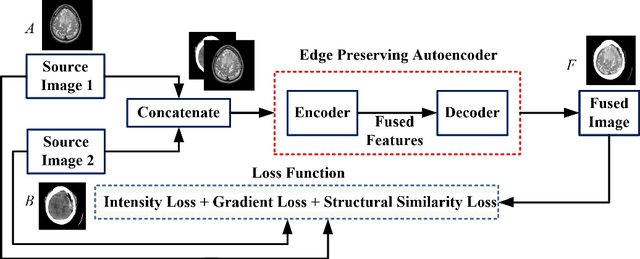


Medical image fusion integrates the complementary diagnostic information of the source image modalities for improved visualization and analysis of underlying anomalies. Recently, deep learning-based models have excelled the conventional fusion methods by executing feature extraction, feature selection, and feature fusion tasks, simultaneously. However, most of the existing convolutional neural network (CNN) architectures use conventional pooling or strided convolutional strategies to downsample the feature maps. It causes the blurring or loss of important diagnostic information and edge details available in the source images and dilutes the efficacy of the feature extraction process. Therefore, this paper presents an end-to-end unsupervised fusion model for multimodal medical images based on an edge-preserving dense autoencoder network. In the proposed model, feature extraction is improved by using wavelet decomposition-based attention pooling of feature maps. This helps in preserving the fine edge detail information present in both the source images and enhances the visual perception of fused images. Further, the proposed model is trained on a variety of medical image pairs which helps in capturing the intensity distributions of the source images and preserves the diagnostic information effectively. Substantial experiments are conducted which demonstrate that the proposed method provides improved visual and quantitative results as compared to the other state-of-the-art fusion methods.