 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Medical Neurological Image Fusion using Wavelet Pooled Edge Preserving Autoencoder
Paper and Code
Oct 18, 2023
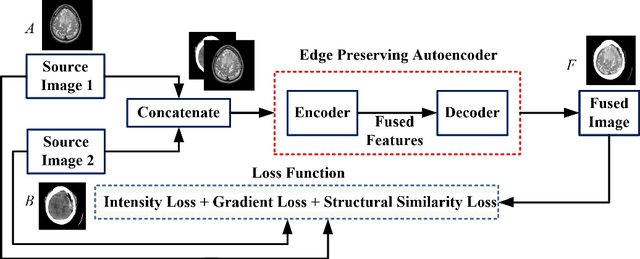


Medical image fusion integrates the complementary diagnostic information of the source image modalities for improved visualization and analysis of underlying anomalies. Recently, deep learning-based models have excelled the conventional fusion methods by executing feature extraction, feature selection, and feature fusion tasks, simultaneously. However, most of the existing convolutional neural network (CNN) architectures use conventional pooling or strided convolutional strategies to downsample the feature maps. It causes the blurring or loss of important diagnostic information and edge details available in the source images and dilutes the efficacy of the feature extraction process. Therefore, this paper presents an end-to-end unsupervised fusion model for multimodal medical images based on an edge-preserving dense autoencoder network. In the proposed model, feature extraction is improved by using wavelet decomposition-based attention pooling of feature maps. This helps in preserving the fine edge detail information present in both the source images and enhances the visual perception of fused images. Further, the proposed model is trained on a variety of medical image pairs which helps in capturing the intensity distributions of the source images and preserves the diagnostic information effectively. Substantial experiments are conducted which demonstrate that the proposed method provides improved visual and quantitative results as compared to the other state-of-the-art fusion methods.