 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Iterative Training of Convolutional Neural Networks for Tree Skeleton Segmentation
Oct 16, 2020
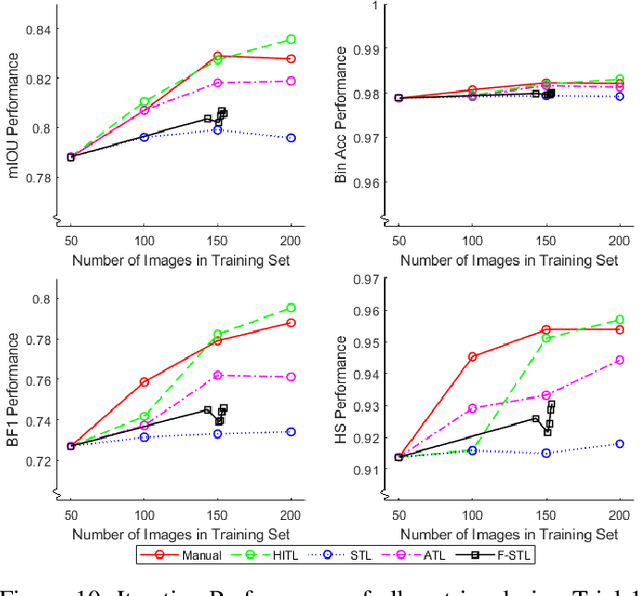

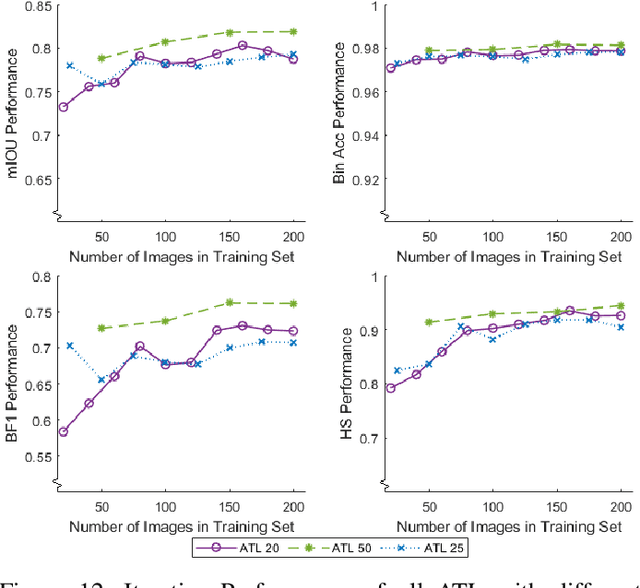
Training of convolutional neural networks for semantic segmentation requires accurate pixel-wise labeling. Depending on the application this can require large amounts of human effort. The human-in-the-loop method reduces labeling effort but still requires human intervention for a selection of images. This paper describes a new iterative training method: Automating-the-loop. Automating-the-loop aims to replicate the human adjustment in human-in-the-loop, with an automated process. Thereby, removing human intervention during the iterative process and drastically reducing labeling effort. Using the application of segmented apple tree detection, we compare human-in-the-loop, Self Training Loop, Filtered-Self Training Loop (semi-supervised learning) and our proposed method automating-the-loop. These methods are used to train U-Net, a deep learning based convolutional neural network. The results are presented and analyzed on both traditional performance metrics and a new metric, Horizontal Scan. It is shown that the new method of automating-the-loop greatly reduces the labeling effort while generating a network with comparable performance to both human-in-the-loop and completely manual labeling.
Semantic Segmentation for Partially Occluded Apple Trees Based on Deep Learning
Oct 14, 2020
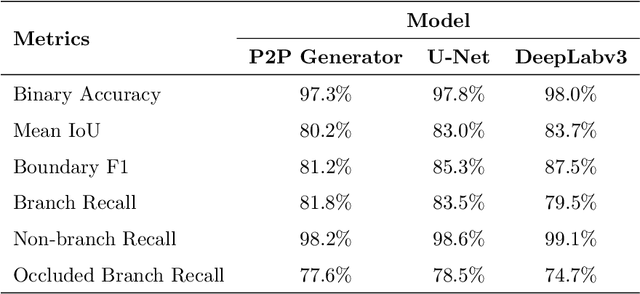


Fruit tree pruning and fruit thinning require a powerful vision system that can provide high resolution segmentation of the fruit trees and their branches. However, recent works only consider the dormant season, where there are minimal occlusions on the branches or fit a polynomial curve to reconstruct branch shape and hence, losing information about branch thickness. In this work, we apply two state-of-the-art supervised learning models U-Net and DeepLabv3, and a conditional Generative Adversarial Network Pix2Pix (with and without the discriminator) to segment partially occluded 2D-open-V apple trees. Binary accuracy, Mean IoU, Boundary F1 score and Occluded branch recall were used to evaluate the performances of the models. DeepLabv3 outperforms the other models at Binary accuracy, Mean IoU and Boundary F1 score, but is surpassed by Pix2Pix (without discriminator) and U-Net in Occluded branch recall. We define two difficulty indices to quantify the difficulty of the task: (1) Occlusion Difficulty Index and (2) Depth Difficulty Index. We analyze the worst 10 images in both difficulty indices by means of Branch Recall and Occluded Branch Recall. U-Net outperforms the other two models in the current metrics. On the other hand, Pix2Pix (without discriminator) provides more information on branch paths, which are not reflected by the metrics. This highlights the need for more specific metrics on recovering occluded information. Furthermore, this shows the usefulness of image-transfer networks for hallucination behind occlusions. Future work is required to further enhance the models to recover more information from occlusions such that this technology can be applied to automating agricultural tasks in a commercial environment.