 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Acoustic Cues and Paralinguistic Embeddings to Detect Expression from Voice
Jun 28, 2019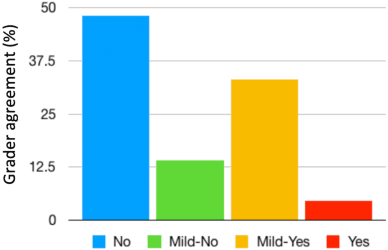

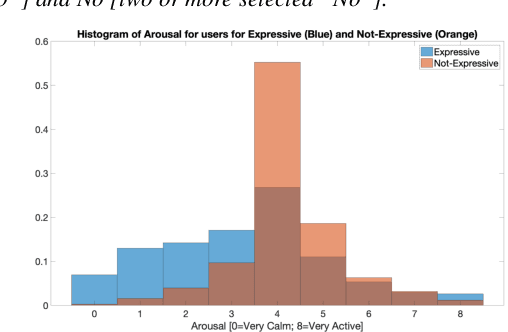

Millions of people reach out to digital assistants such as Siri every day, asking for information, making phone calls, seeking assistance, and much more. The expectation is that such assistants should understand the intent of the users query. Detecting the intent of a query from a short, isolated utterance is a difficult task. Intent cannot always be obtained from speech-recognized transcriptions. A transcription driven approach can interpret what has been said but fails to acknowledge how it has been said, and as a consequence, may ignore the expression present in the voice. Our work investigates whether a system can reliably detect vocal expression in queries using acoustic and paralinguistic embedding. Results show that the proposed method offers a relative equal error rate (EER) decrease of 60% compared to a bag-of-word based system, corroborating that expression is significantly represented by vocal attributes, rather than being purely lexical. Addition of emotion embedding helped to reduce the EER by 30% relative to the acoustic embedding, demonstrating the relevance of emotion in expressive voice.