 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCSEG: Decoupled 3D Open-Set Segmentation using Gaussian Splatting
Dec 14, 2024



Open-set 3D segmentation represents a major point of interest for multiple downstream robotics and augmented/virtual reality applications. Recent advances introduce 3D Gaussian Splatting as a computationally efficient representation of the underlying scene. They enable the rendering of novel views while achieving real-time display rates and matching the quality of computationally far more expensive methods. We present a decoupled 3D segmentation pipeline to ensure modularity and adaptability to novel 3D representations and semantic segmentation foundation models. The pipeline proposes class-agnostic masks based on a 3D reconstruction of the scene. Given the resulting class-agnostic masks, we use a class-aware 2D foundation model to add class annotations to the 3D masks. We test this pipeline with 3D Gaussian Splatting and different 2D segmentation models and achieve better performance than more tailored approaches while also significantly increasing the modularity.
UnScene3D: Unsupervised 3D Instance Segmentation for Indoor Scenes
Mar 25, 20233D instance segmentation is fundamental to geometric understanding of the world around us. Existing methods for instance segmentation of 3D scenes rely on supervision from expensive, manual 3D annotations. We propose UnScene3D, the first fully unsupervised 3D learning approach for class-agnostic 3D instance segmentation of indoor scans. UnScene3D first generates pseudo masks by leveraging self-supervised color and geometry features to find potential object regions. We operate on a basis of geometric oversegmentation, enabling efficient representation and learning on high-resolution 3D data. The coarse proposals are then refined through self-training our model on its predictions. Our approach improves over state-of-the-art unsupervised 3D instance segmentation methods by more than 300% Average Precision score, demonstrating effective instance segmentation even in challenging, cluttered 3D scenes.
Language-Grounded Indoor 3D Semantic Segmentation in the Wild
Apr 16, 2022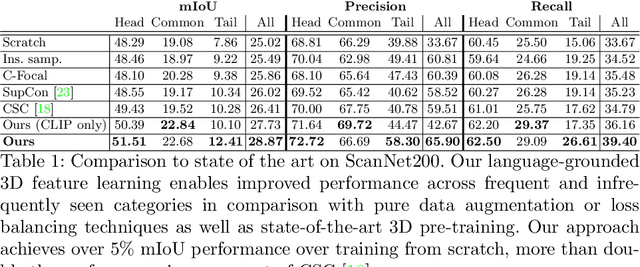
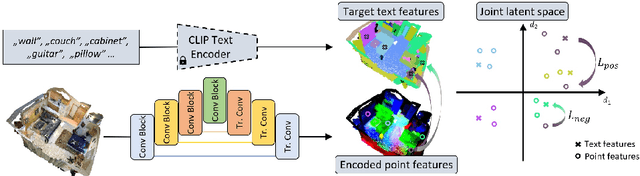
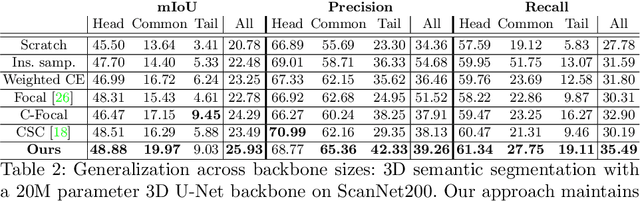
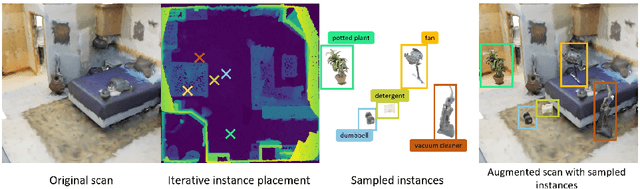
Recent advances in 3D semantic segmentation with deep neural networks have shown remarkable success, with rapid performance increase on available datasets. However, current 3D semantic segmentation benchmarks contain only a small number of categories -- less than 30 for ScanNet and SemanticKITTI, for instance, which are not enough to reflect the diversity of real environments (e.g., semantic image understanding covers hundreds to thousands of classes). Thus, we propose to study a larger vocabulary for 3D semantic segmentation with a new extended benchmark on ScanNet data with 200 class categories, an order of magnitude more than previously studied. This large number of class categories also induces a large natural class imbalance, both of which are challenging for existing 3D semantic segmentation methods. To learn more robust 3D features in this context, we propose a language-driven pre-training method to encourage learned 3D features that might have limited training examples to lie close to their pre-trained text embeddings. Extensive experiments show that our approach consistently outperforms state-of-the-art 3D pre-training for 3D semantic segmentation on our proposed benchmark (+9% relative mIoU), including limited-data scenarios with +25% relative mIoU using only 5% annotations.
LOL: Lidar-Only Odometry and Localization in 3D Point Cloud Maps
Jul 03, 2020


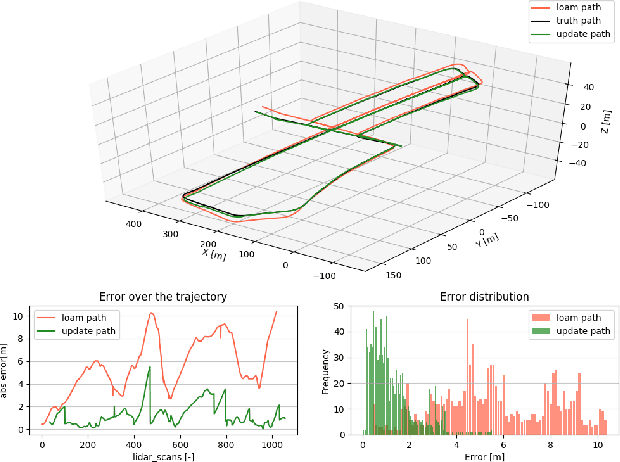
In this paper we deal with the problem of odometry and localization for Lidar-equipped vehicles driving in urban environments, where a premade target map exists to localize against. In our problem formulation, to correct the accumulated drift of the Lidar-only odometry we apply a place recognition method to detect geometrically similar locations between the online 3D point cloud and the a priori offline map. In the proposed system, we integrate a state-of-the-art Lidar-only odometry algorithm with a recently proposed 3D point segment matching method by complementing their advantages. Also, we propose additional enhancements in order to reduce the number of false matches between the online point cloud and the target map, and to refine the position estimation error whenever a good match is detected. We demonstrate the utility of the proposed LOL system on several Kitti datasets of different lengths and environments, where the relocalization accuracy and the precision of the vehicle's trajectory were significantly improved in every case, while still being able to maintain real-time performance.