 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Driven New Drug Recommendation
Oct 11, 2022
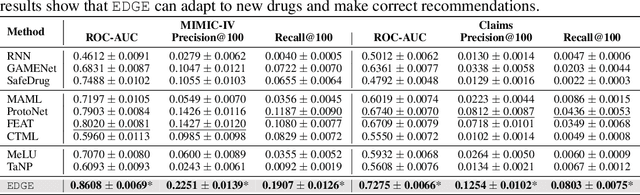


Drug recommendation assists doctors in prescribing personalized medications to patients based on their health conditions. Existing drug recommendation solutions adopt the supervised multi-label classification setup and only work with existing drugs with sufficient prescription data from many patients. However, newly approved drugs do not have much historical prescription data and cannot leverage existing drug recommendation methods. To address this, we formulate the new drug recommendation as a few-shot learning problem. Yet, directly applying existing few-shot learning algorithms faces two challenges: (1) complex relations among diseases and drugs and (2) numerous false-negative patients who were eligible but did not yet use the new drugs. To tackle these challenges, we propose EDGE, which can quickly adapt to the recommendation for a new drug with limited prescription data from a few support patients. EDGE maintains a drug-dependent multi-phenotype few-shot learner to bridge the gap between existing and new drugs. Specifically, EDGE leverages the drug ontology to link new drugs to existing drugs with similar treatment effects and learns ontology-based drug representations. Such drug representations are used to customize the metric space of the phenotype-driven patient representations, which are composed of a set of phenotypes capturing complex patient health status. Lastly, EDGE eliminates the false-negative supervision signal using an external drug-disease knowledge base. We evaluate EDGE on two real-world datasets: the public EHR data (MIMIC-IV) and private industrial claims data. Results show that EDGE achieves 7.3% improvement on the ROC-AUC score over the best baseline.
AutoMap: Automatic Medical Code Mapping for Clinical Prediction Model Deployment
Mar 04, 2022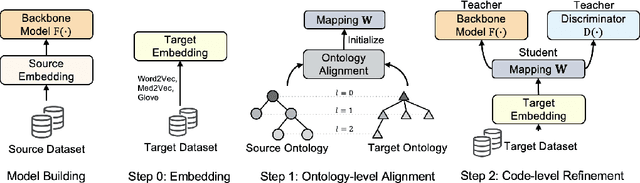
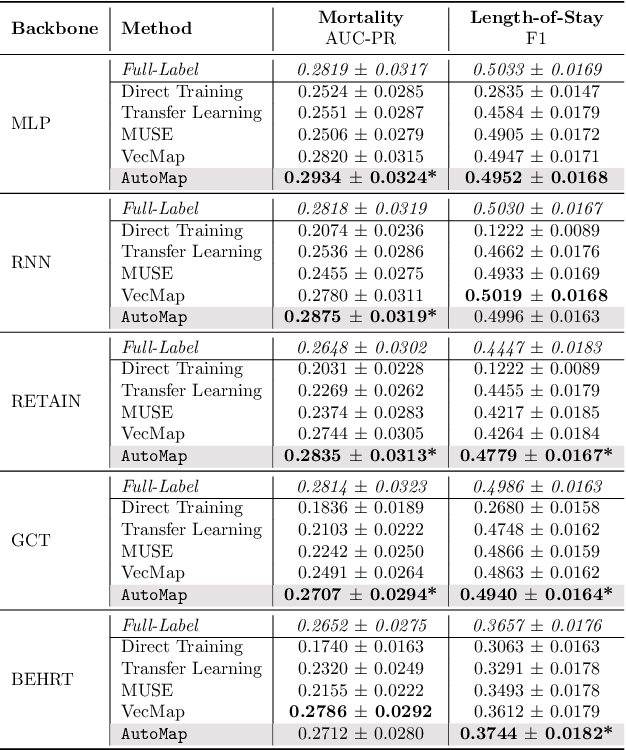


Given a deep learning model trained on data from a source site, how to deploy the model to a target hospital automatically? How to accommodate heterogeneous medical coding systems across different hospitals? Standard approaches rely on existing medical code mapping tools, which have significant practical limitations. To tackle this problem, we propose AutoMap to automatically map the medical codes across different EHR systems in a coarse-to-fine manner: (1) Ontology-level Alignment: We leverage the ontology structure to learn a coarse alignment between the source and target medical coding systems; (2) Code-level Refinement: We refine the alignment at a fine-grained code level for the downstream tasks using a teacher-student framework. We evaluate AutoMap using several deep learning models with two real-world EHR datasets: eICU and MIMIC-III. Results show that AutoMap achieves relative improvements up to 3.9% (AUC-ROC) and 8.7% (AUC-PR) for mortality prediction, and up to 4.7% (AUC-ROC) and 3.7% (F1) for length-of-stay estimation. Further, we show that AutoMap can provide accurate mapping across coding systems. Lastly, we demonstrate that AutoMap can adapt to the two challenging scenarios: (1) mapping between completely different coding systems and (2) between completely different hospitals.