 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Low-latency Optical Phase Sensor Array
May 03, 2023



Optical phase measurement is critical for many applications and traditional approaches often suffer from mechanical instability, temporal latency, and computational complexity. In this paper, we describe compact phase sensor arrays based on integrated photonics, which enable accurate and scalable reference-free phase sensing in a few measurement steps. This is achieved by connecting multiple two-port phase sensors into a graph to measure relative phases between neighboring and distant spatial locations. We propose an efficient post-processing algorithm, as well as circuit design rules to reduce random and biased error accumulations. We demonstrate the effectiveness of our system in both simulations and experiments with photonic integrated circuits. The proposed system measures the optical phase directly without the need for external references or spatial light modulators, thus providing significant benefits for applications including microscope imaging and optical phased arrays.
Scalable and self-correcting photonic computation using balanced photonic binary tree cascades
Oct 30, 2022Programmable unitary photonic networks that interfere hundreds of modes are emerging as a key technology in energy-efficient sensing, machine learning, cryptography, and linear optical quantum computing applications. In this work, we establish a theoretical framework to quantify error tolerance and scalability in a more general class of "binary tree cascade'' programmable photonic networks that accept up to tens of thousands of discrete input modes $N$. To justify this scalability claim, we derive error tolerance and configuration time that scale with $\log_2 N$ for balanced trees versus $N$ in unbalanced trees, despite the same number of total components. Specifically, we use second-order perturbation theory to compute phase sensitivity in each waveguide of balanced and unbalanced networks, and we compute the statistics of the sensitivity given random input vectors. We also evaluate such networks after they self-correct, or self-configure, themselves for errors in the circuit due to fabrication error and environmental drift. Our findings have important implications for scaling photonic circuits to much larger circuit sizes; this scaling is particularly critical for applications such as principal component analysis and fast Fourier transforms, which are important algorithms for machine learning and signal processing.
Experimentally realized in situ backpropagation for deep learning in nanophotonic neural networks
May 17, 2022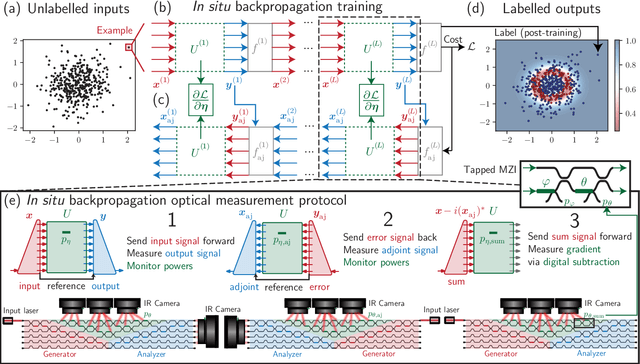
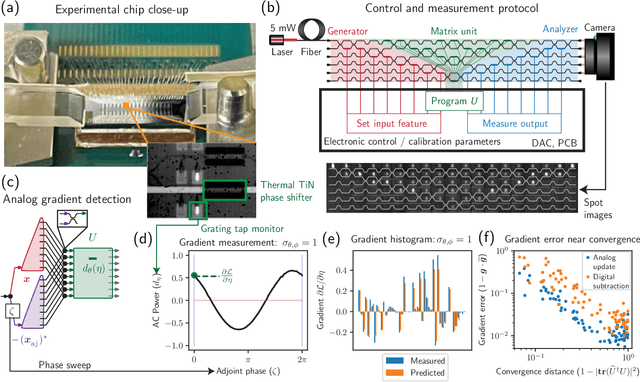
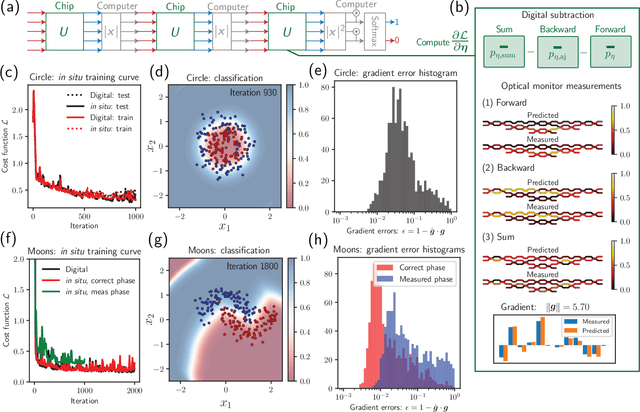
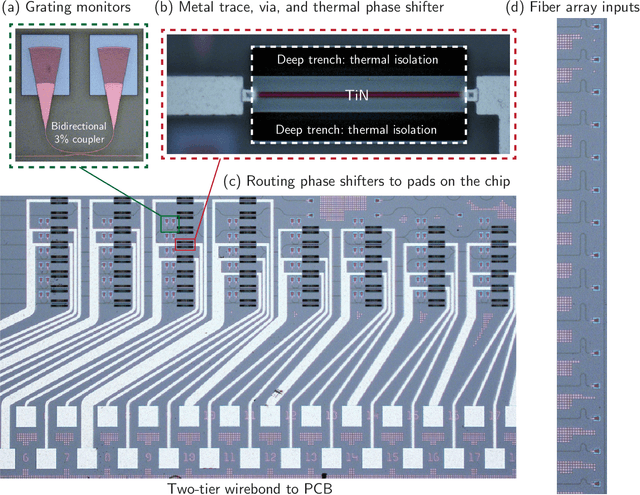
Neural networks are widely deployed models across many scientific disciplines and commercial endeavors ranging from edge computing and sensing to large-scale signal processing in data centers. The most efficient and well-entrenched method to train such networks is backpropagation, or reverse-mode automatic differentiation. To counter an exponentially increasing energy budget in the artificial intelligence sector, there has been recent interest in analog implementations of neural networks, specifically nanophotonic neural networks for which no analog backpropagation demonstration exists. We design mass-manufacturable silicon photonic neural networks that alternately cascade our custom designed "photonic mesh" accelerator with digitally implemented nonlinearities. These reconfigurable photonic meshes program computationally intensive arbitrary matrix multiplication by setting physical voltages that tune the interference of optically encoded input data propagating through integrated Mach-Zehnder interferometer networks. Here, using our packaged photonic chip, we demonstrate in situ backpropagation for the first time to solve classification tasks and evaluate a new protocol to keep the entire gradient measurement and update of physical device voltages in the analog domain, improving on past theoretical proposals. Our method is made possible by introducing three changes to typical photonic meshes: (1) measurements at optical "grating tap" monitors, (2) bidirectional optical signal propagation automated by fiber switch, and (3) universal generation and readout of optical amplitude and phase. After training, our classification achieves accuracies similar to digital equivalents even in presence of systematic error. Our findings suggest a new training paradigm for photonics-accelerated artificial intelligence based entirely on a physical analog of the popular backpropagation technique.
Multibeam Free Space Optics Receiver Enabled by a Programmable Photonic Mesh
Dec 16, 2021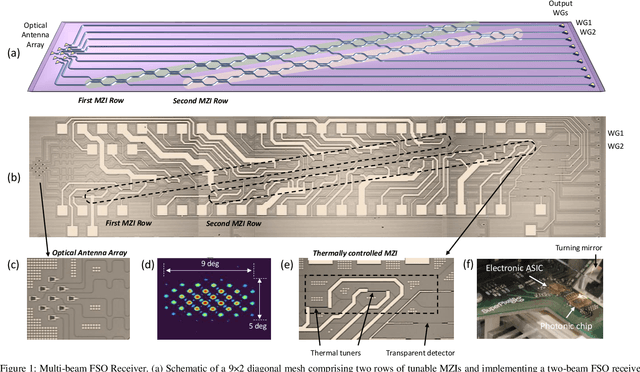
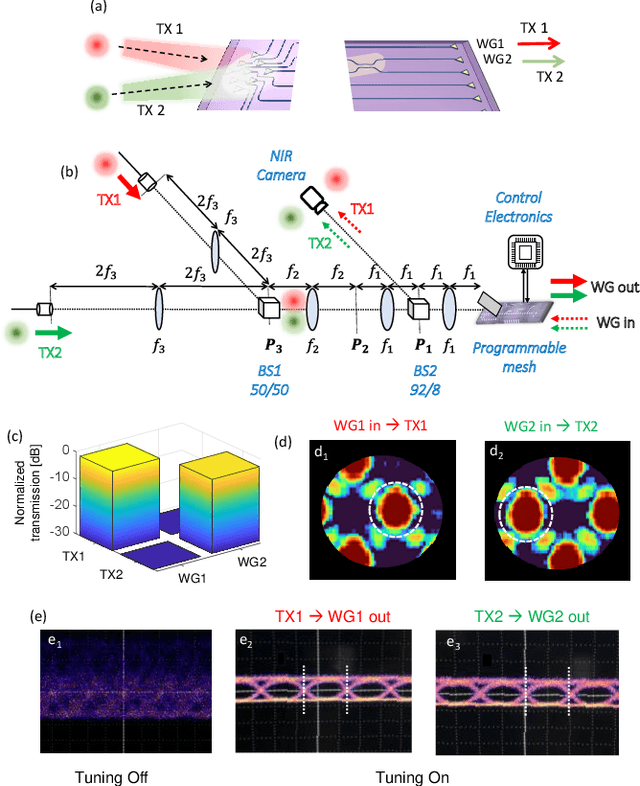
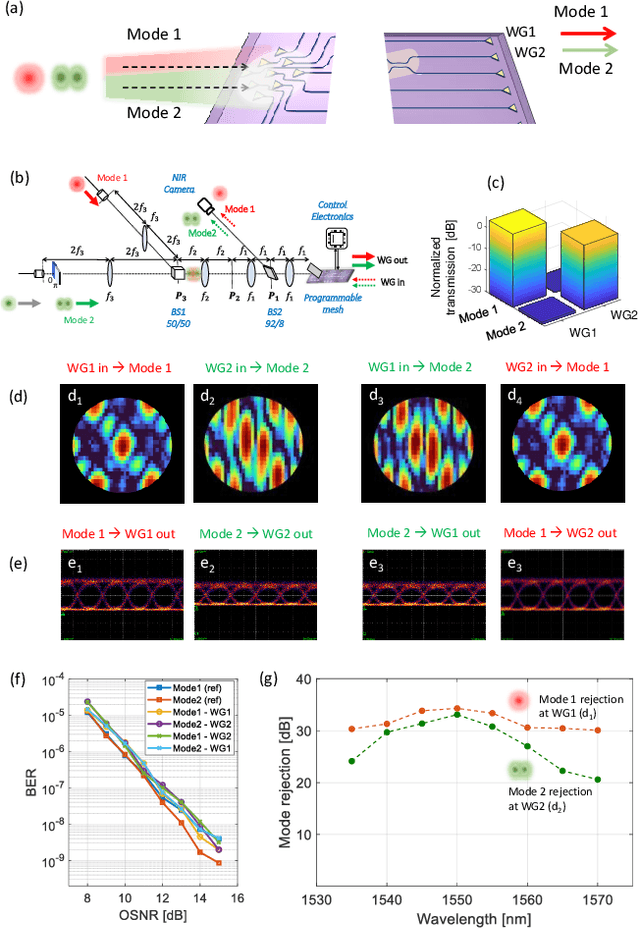
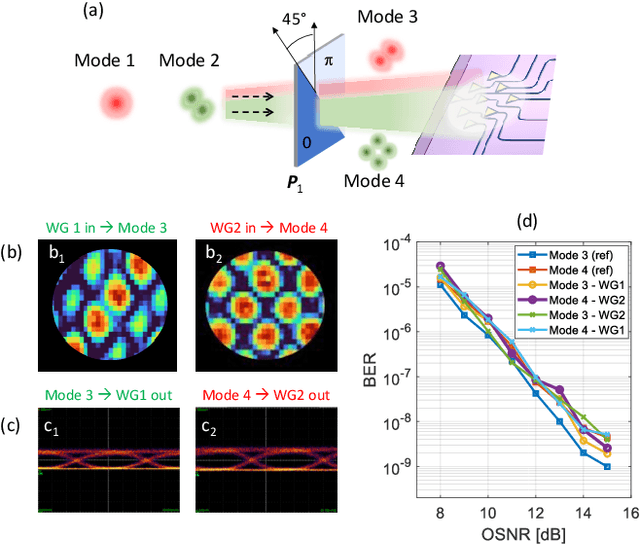
Free-space optics (FSO) is an attractive technology to meet the ever-growing demand for wireless bandwidth in next generation networks. To increase the spectral efficiency of FSO links, transmission over spatial division multiplexing (SDM) can be exploited, where orthogonal light beams have to be shaped according to suitable amplitude, phase, and polarization profiles. In this work, we show that a programmable photonic circuits, consisting of a silicon photonic mesh of tunable Mach-Zehnder Interferometers (MZIs) can be used as an adaptive multibeam receiver for a FSO communication link. The circuit can self-configure to simultaneously receive and separate, with negligible mutual crosstalk, signals carried by orthogonal FSO beams sharing the same wavelength and polarization. This feature is demonstrated on signal pairs either arriving at the receiver from orthogonal directions (direction-diversity) or being shaped according to different orthogonal spatial modes (mode-diversity), even in the presence of some mixing during propagation. The performance of programmable mesh as an adaptive multibeam receiver is assessed by means of data channel transmission at 10 Gbit/s a wavelength of 1550 nm, but the optical bandwidth of the receiver (>40 nm) allows its use at much higher data rates as well as in wavelength-division multiplexing SDM communication links.
Parallel fault-tolerant programming of an arbitrary feedforward photonic network
Sep 11, 2019



Reconfigurable photonic mesh networks of tunable beamsplitter nodes can linearly transform $N$-dimensional vectors representing input modal amplitudes of light for applications such as energy-efficient machine learning hardware, quantum information processing, and mode demultiplexing. Such photonic meshes are typically programmed and/or calibrated by tuning or characterizing each beam splitter one-by-one, which can be time-consuming and can limit scaling to larger meshes. Here we introduce a graph-topological approach that defines the general class of feedforward networks commonly used in such applications and identifies columns of non-interacting nodes that can be adjusted simultaneously. By virtue of this approach, we can calculate the necessary input vectors to program entire columns of nodes in parallel by simultaneously nullifying the power in one output of each node via optoelectronic feedback onto adjustable phase shifters or couplers. This parallel nullification approach is fault-tolerant to fabrication errors, requiring no prior knowledge or calibration of the node parameters, and can reduce the programming time by a factor of order $N$ to being proportional to the optical depth (or number of node columns in the device). As a demonstration, we simulate our programming protocol on a feedforward optical neural network model trained to classify handwritten digit images from the MNIST dataset with up to 98% validation accuracy.
Matrix optimization on universal unitary photonic devices
Aug 02, 2018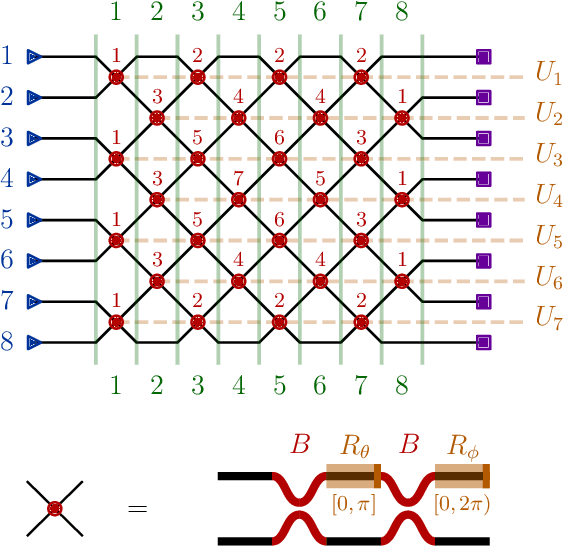
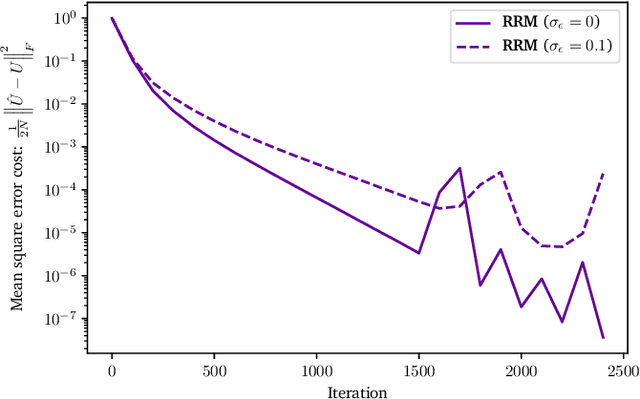
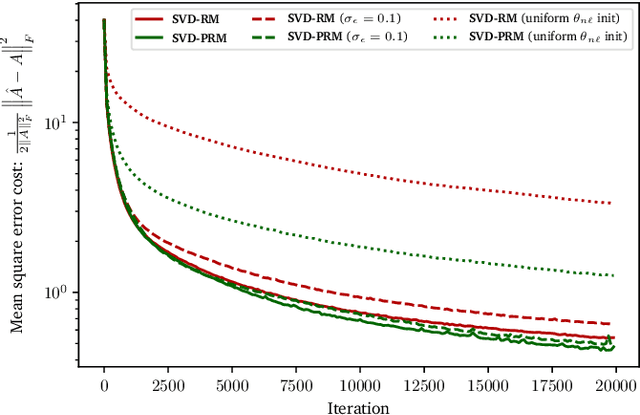
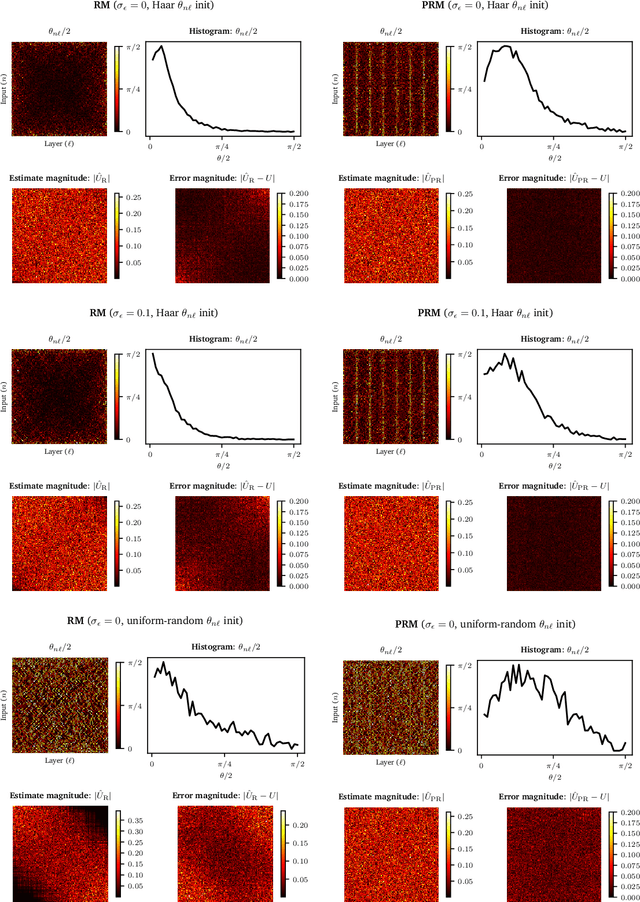
Universal unitary photonic devices are capable of applying arbitrary unitary transformations to multi-port coherent light inputs and provide a promising hardware platform for fast and energy-efficient machine learning. We address the problem of training universal photonic devices composed of meshes of tunable beamsplitters to learn unknown unitary matrices. The locally-interacting nature of the mesh components limits the fidelity of the learned matrices if phase shifts are randomly initialized. We propose an initialization procedure derived from the Haar measure over unitary matrices that overcomes this limitation. We also embed various model architectures within a standard rectangular mesh "canvas," and our numerical experiments show significantly improved scalability and training speed, even in the presence of fabrication errors.