 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Advanced LLMs to Enhance Smaller LLMs: An Interpretable Knowledge Distillation Approach
Aug 13, 2024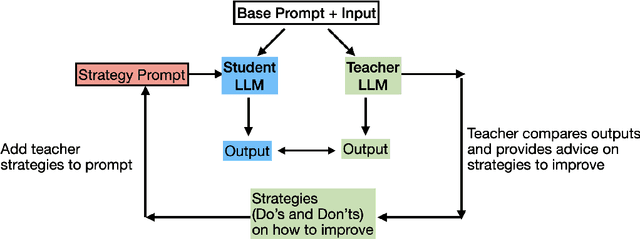

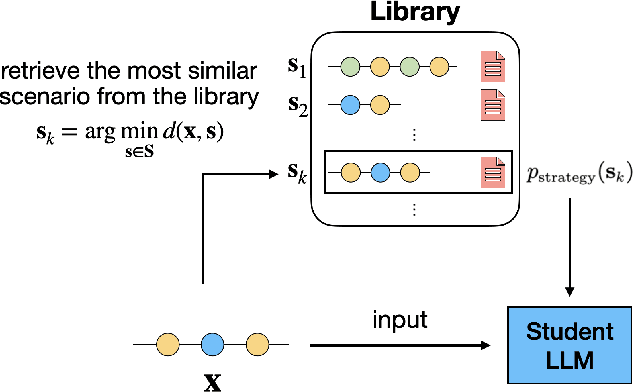

Advanced Large language models (LLMs) like GPT-4 or LlaMa 3 provide superior performance in complex human-like interactions. But they are costly, or too large for edge devices such as smartphones and harder to self-host, leading to security and privacy concerns. This paper introduces a novel interpretable knowledge distillation approach to enhance the performance of smaller, more economical LLMs that firms can self-host. We study this problem in the context of building a customer service agent aimed at achieving high customer satisfaction through goal-oriented dialogues. Unlike traditional knowledge distillation, where the "student" model learns directly from the "teacher" model's responses via fine-tuning, our interpretable "strategy" teaching approach involves the teacher providing strategies to improve the student's performance in various scenarios. This method alternates between a "scenario generation" step and a "strategies for improvement" step, creating a customized library of scenarios and optimized strategies for automated prompting. The method requires only black-box access to both student and teacher models; hence it can be used without manipulating model parameters. In our customer service application, the method improves performance, and the learned strategies are transferable to other LLMs and scenarios beyond the training set. The method's interpretabilty helps safeguard against potential harms through human audit.
Predicting Elevated Risk of Hospitalization Following Emergency Department Discharges
Jun 28, 2024



Hospitalizations that follow closely on the heels of one or more emergency department visits are often symptoms of missed opportunities to form a proper diagnosis. These diagnostic errors imply a failure to recognize the need for hospitalization and deliver appropriate care, and thus also bear important connotations for patient safety. In this paper, we show how data mining techniques can be applied to a large existing hospitalization data set to learn useful models that predict these upcoming hospitalizations with high accuracy. Specifically, we use an ensemble of logistics regression, na\"ive Bayes and association rule classifiers to successfully predict hospitalization within 3, 7 and 14 days of an emergency department discharge. Aside from high accuracy, one of the advantages of the techniques proposed here is that the resulting classifier is easily inspected and interpreted by humans so that the learned rules can be readily operationalized. These rules can then be easily distributed and applied directly by physicians in emergency department settings to predict the risk of early admission prior to discharging their emergency department patients.
Personalized Path Recourse
Dec 14, 2023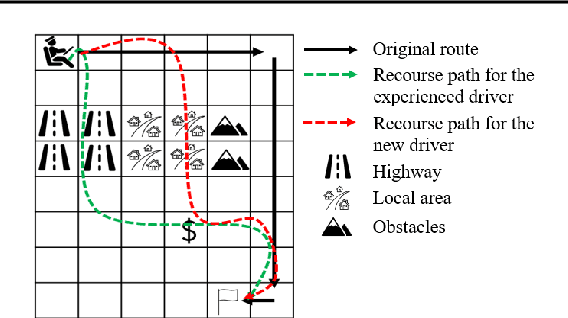

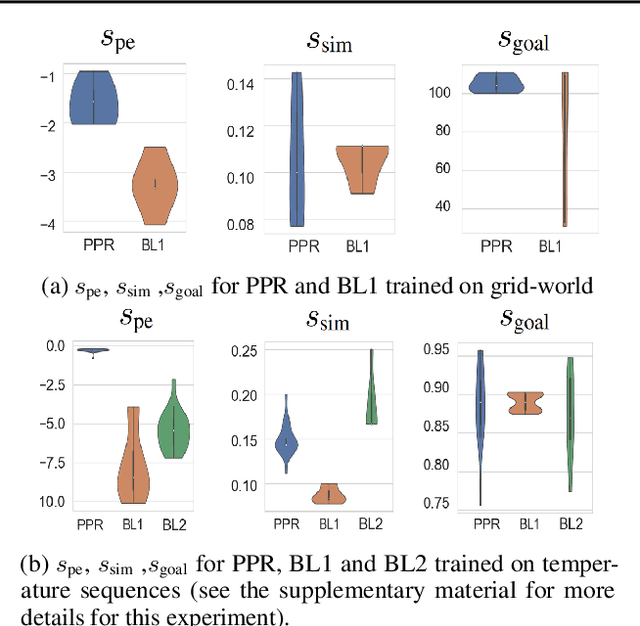

This paper introduces Personalized Path Recourse, a novel method that generates recourse paths for an agent. The objective is to achieve desired goals (e.g., better outcomes compared to the agent's original paths of action), while ensuring a high similarity to the agent's original paths and being personalized to the agent. Personalization refers to the extent to which the new path is tailored to the agent's observed behavior patterns from their policy function. We train a personalized recourse agent to generate such personalized paths, which are obtained using reward functions that consider the goal, similarity, and personalization. The proposed method is applicable to both reinforcement learning and supervised learning settings for correcting or improving sequences of actions or sequences of data to achieve a pre-determined goal. The method is evaluated in various settings and demonstrates promising results.
Interpretable Sequence Classification Via Prototype Trajectory
Jul 03, 2020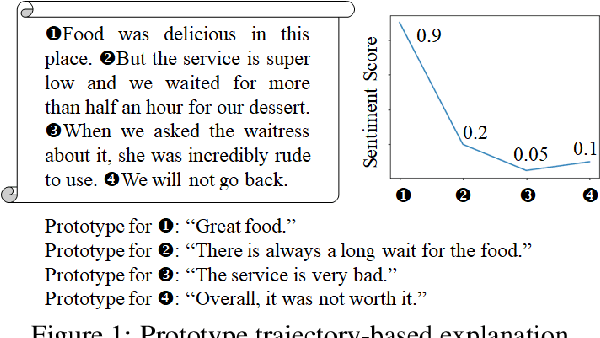
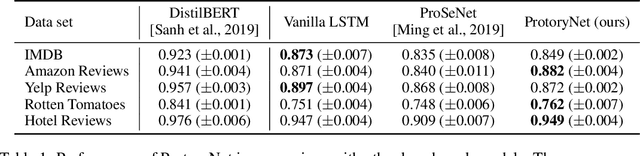

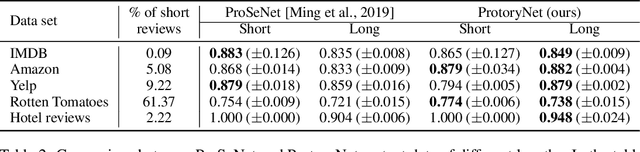
We propose a novel interpretable recurrent neural network (RNN) model, called ProtoryNet, in which we introduce a new concept of prototype trajectories. Motivated by the prototype theory in modern linguistics, ProtoryNet makes a prediction by finding the most similar prototype for each sentence in a text sequence and feeding an RNN backbone with the proximity of each of the sentences to the prototypes. The RNN backbone then captures the temporal pattern of the prototypes, to which we refer as prototype trajectories. The prototype trajectories enable intuitive, fine-grained interpretation of how the model reached to the final prediction, resembling the process of how humans analyze paragraphs. Experiments conducted on multiple public data sets reveal that the proposed method not only is more interpretable but also is more accurate than the current state-of-the-art prototype-based method. Furthermore, we report a survey result indicating that human users find ProtoryNet more intuitive and easier to understand, compared to the other prototype-based methods.