 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Advanced LLMs to Enhance Smaller LLMs: An Interpretable Knowledge Distillation Approach
Paper and Code
Aug 13, 2024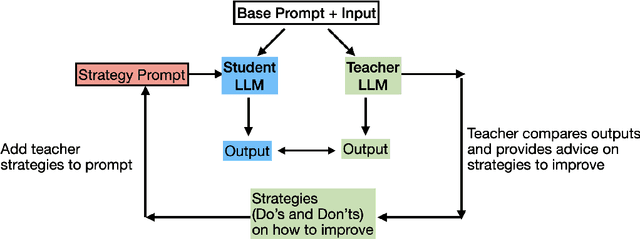

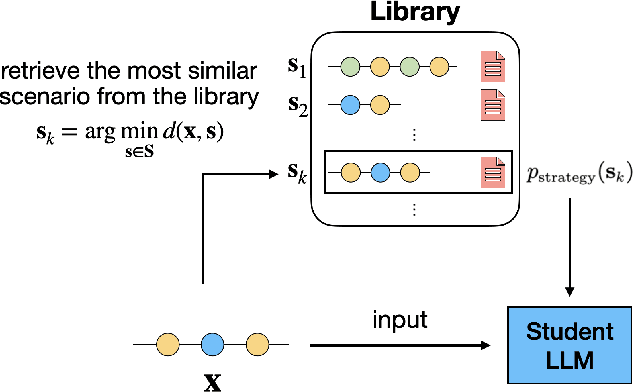

Advanced Large language models (LLMs) like GPT-4 or LlaMa 3 provide superior performance in complex human-like interactions. But they are costly, or too large for edge devices such as smartphones and harder to self-host, leading to security and privacy concerns. This paper introduces a novel interpretable knowledge distillation approach to enhance the performance of smaller, more economical LLMs that firms can self-host. We study this problem in the context of building a customer service agent aimed at achieving high customer satisfaction through goal-oriented dialogues. Unlike traditional knowledge distillation, where the "student" model learns directly from the "teacher" model's responses via fine-tuning, our interpretable "strategy" teaching approach involves the teacher providing strategies to improve the student's performance in various scenarios. This method alternates between a "scenario generation" step and a "strategies for improvement" step, creating a customized library of scenarios and optimized strategies for automated prompting. The method requires only black-box access to both student and teacher models; hence it can be used without manipulating model parameters. In our customer service application, the method improves performance, and the learned strategies are transferable to other LLMs and scenarios beyond the training set. The method's interpretabilty helps safeguard against potential harms through human audit.