 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safety Modulator Actor-Critic Method in Model-Free Safe Reinforcement Learning and Application in UAV Hovering
Oct 09, 2024
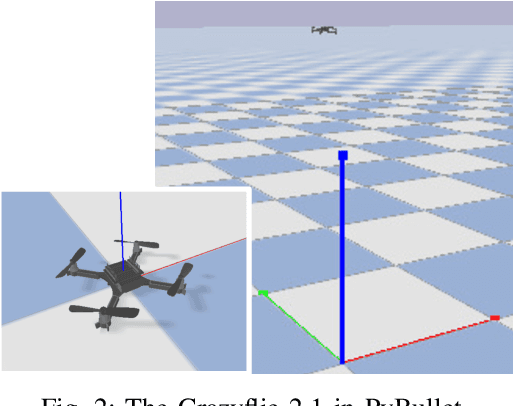


This paper proposes a safety modulator actor-critic (SMAC) method to address safety constraint and overestimation mitigation in model-free safe reinforcement learning (RL). A safety modulator is developed to satisfy safety constraints by modulating actions, allowing the policy to ignore safety constraint and focus on maximizing reward. Additionally, a distributional critic with a theoretical update rule for SMAC is proposed to mitigate the overestimation of Q-values with safety constraints. Both simulation and real-world scenarios experiments on Unmanned Aerial Vehicles (UAVs) hovering confirm that the SMAC can effectively maintain safety constraints and outperform mainstream baseline algorithms.
Robust Kernel-based Distribution Regression
Apr 21, 2021Regularization schemes for regression have been widely studied in learning theory and inverse problems. In this paper, we study distribution regression (DR) which involves two stages of sampling, and aims at regressing from probability measures to real-valued responses over a reproducing kernel Hilbert space (RKHS). Recently, theoretical analysis on DR has been carried out via kernel ridge regression and several learning behaviors have been observed. However, the topic has not been explored and understood beyond the least square based DR. By introducing a robust loss function $l_{\sigma}$ for two-stage sampling problems, we present a novel robust distribution regression (RDR) scheme. With a windowing function $V$ and a scaling parameter $\sigma$ which can be appropriately chosen, $l_{\sigma}$ can include a wide range of popular used loss functions that enrich the theme of DR. Moreover, the loss $l_{\sigma}$ is not necessarily convex, hence largely improving the former regression class (least square) in the literature of DR. The learning rates under different regularity ranges of the regression function $f_{\rho}$ are comprehensively studied and derived via integral operator techniques. The scaling parameter $\sigma$ is shown to be crucial in providing robustness and satisfactory learning rates of RDR.
Estimates on Learning Rates for Multi-Penalty Distribution Regression
Jun 16, 2020This paper is concerned with functional learning by utilizing two-stage sampled distribution regression. We study a multi-penalty regularization algorithm for distribution regression under the framework of learning theory. The algorithm aims at regressing to real valued outputs from probability measures. The theoretical analysis on distribution regression is far from maturity and quite challenging, since only second stage samples are observable in practical setting. In the algorithm, to transform information from samples, we embed the distributions to a reproducing kernel Hilbert space $\mathcal{H}_K$ associated with Mercer kernel $K$ via mean embedding technique. The main contribution of the paper is to present a novel multi-penalty regularization algorithm to capture more features of distribution regression and derive optimal learning rates for the algorithm. The work also derives learning rates for distribution regression in the nonstandard setting $f_{\rho}\notin\mathcal{H}_K$, which is not explored in existing literature. Moreover, we propose a distribution regression-based distributed learning algorithm to face large-scale data or information challenge. The optimal learning rates are derived for the distributed learning algorithm. By providing new algorithms and showing their learning rates, we improve the existing work in different aspects in the literature.