 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember and Forget Experience Replay for Multi-Agent Reinforcement Learning
Mar 24, 2022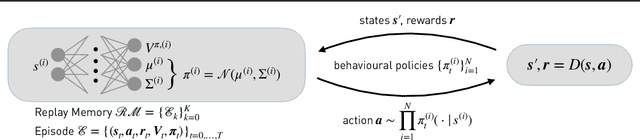

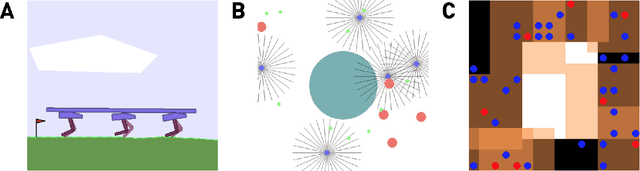
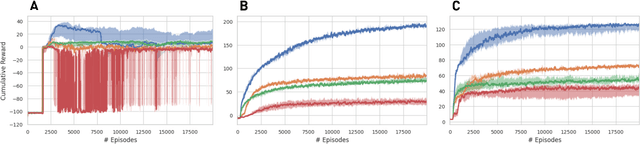
We present the extension of the Remember and Forget for Experience Replay (ReF-ER) algorithm to Multi-Agent Reinforcement Learning (MARL). {ReF-ER} was shown to outperform state of the art algorithms for continuous control in problems ranging from the OpenAI Gym to complex fluid flows. In MARL, the dependencies between the agents are included in the state-value estimator and the environment dynamics are modeled via the importance weights used by ReF-ER. In collaborative environments, we find the best performance when the value is estimated using individual rewards and we ignore the effects of other actions on the transition map. We benchmark the performance of ReF-ER MARL on the Stanford Intelligent Systems Laboratory (SISL) environments. We find that employing a single feed-forward neural network for the policy and the value function in ReF-ER MARL, outperforms state of the art algorithms that rely on complex neural network architectures.