 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-layer Gaussian Process for Motor Symptom Estimation in People with Parkinson's Disease
Sep 27, 2018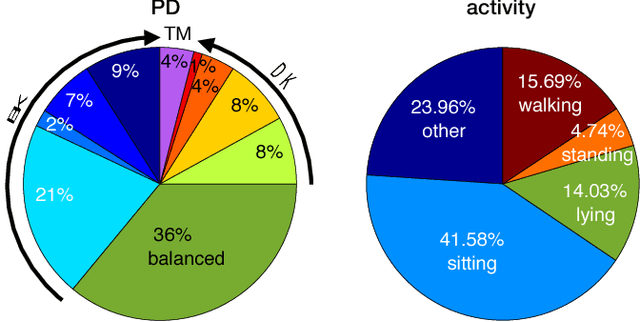
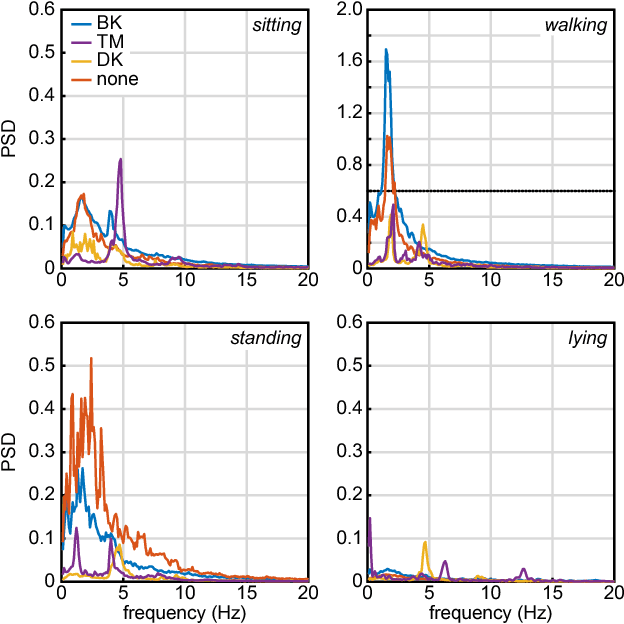
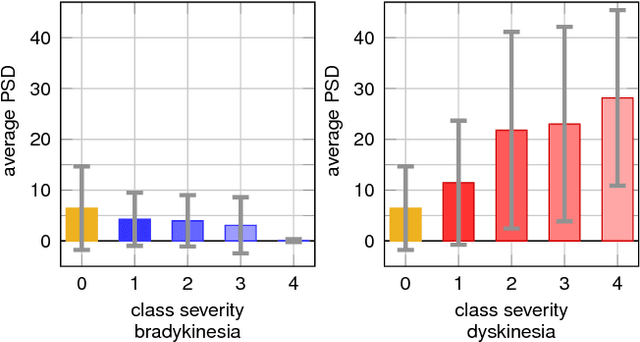
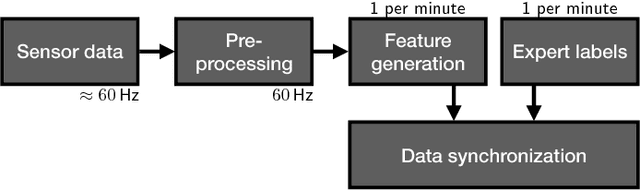
The assessment of Parkinson's disease (PD) poses a significant challenge as it is influenced by various factors which lead to a complex and fluctuating symptom manifestation. Thus, a frequent and objective PD assessment is highly valuable for effective health management of people with Parkinson's disease (PwP). Here, we propose a method for monitoring PwP by stochastically modeling the relationships between their wrist movements during unscripted daily activities and corresponding annotations about clinical displays of movement abnormalities. We approach the estimation of PD motor signs by independently modeling and hierarchically stacking Gaussian process models for three classes of commonly observed movement abnormalities in PwP including tremor, (non-tremulous) bradykinesia, and (non-tremulous) dyskinesia. We use clinically adopted severity measures as annotations for training the models, thus allowing our multi-layer Gaussian process prediction models to estimate not only their presence but also their severities. The experimental validation of our approach demonstrates strong agreement of the model predictions with these PD annotations. Our results show the proposed method produces promising results in objective monitoring of movement abnormalities of PD in the presence of arbitrary and unknown voluntary motions, and makes an important step towards continuous monitoring of PD in the home environment.
Data Augmentation of Wearable Sensor Data for Parkinson's Disease Monitoring using Convolutional Neural Networks
Nov 08, 2017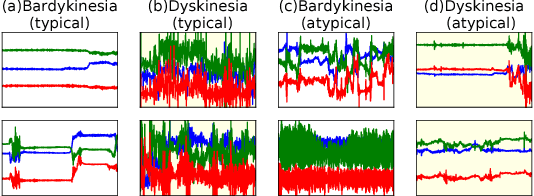
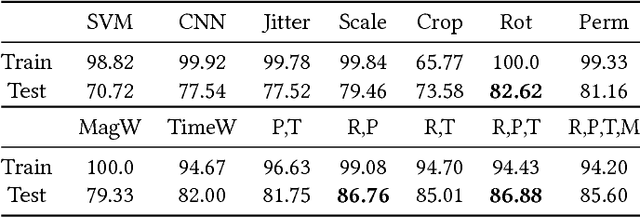

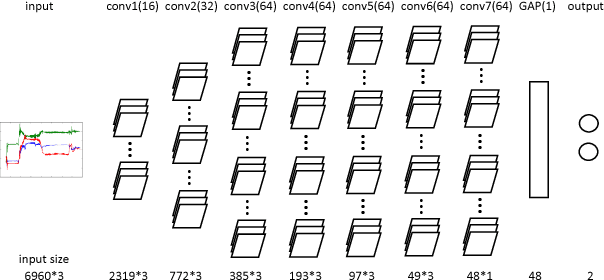
While convolutional neural networks (CNNs) have been successfully applied to many challenging classification applications, they typically require large datasets for training. When the availability of labeled data is limited, data augmentation is a critical preprocessing step for CNNs. However, data augmentation for wearable sensor data has not been deeply investigated yet. In this paper, various data augmentation methods for wearable sensor data are proposed. The proposed methods and CNNs are applied to the classification of the motor state of Parkinson's Disease patients, which is challenging due to small dataset size, noisy labels, and large intra-class variability. Appropriate augmentation improves the classification performance from 77.54\% to 86.88\%.