 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValid Conformal Prediction for Dynamic GNNs
May 29, 2024Graph neural networks (GNNs) are powerful black-box models which have shown impressive empirical performance. However, without any form of uncertainty quantification, it can be difficult to trust such models in high-risk scenarios. Conformal prediction aims to address this problem, however, an assumption of exchangeability is required for its validity which has limited its applicability to static graphs and transductive regimes. We propose to use unfolding, which allows any existing static GNN to output a dynamic graph embedding with exchangeability properties. Using this, we extend the validity of conformal prediction to dynamic GNNs in both transductive and semi-inductive regimes. We provide a theoretical guarantee of valid conformal prediction in these cases and demonstrate the empirical validity, as well as the performance gains, of unfolded GNNs against standard GNN architectures on both simulated and real datasets.
A Simple and Powerful Framework for Stable Dynamic Network Embedding
Nov 14, 2023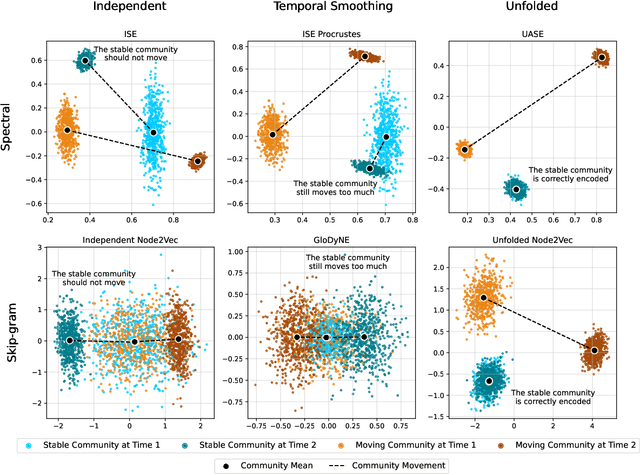
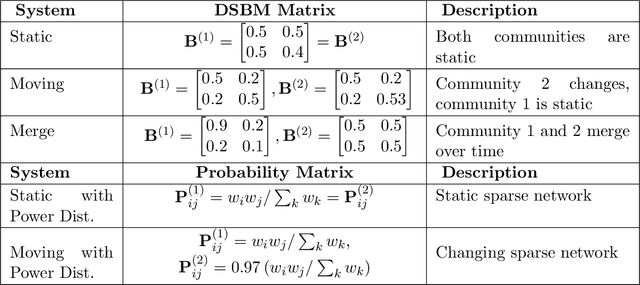
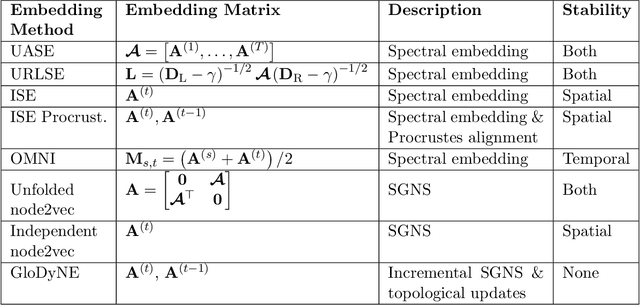
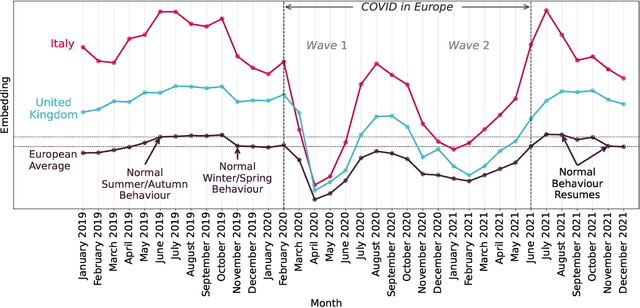
In this paper, we address the problem of dynamic network embedding, that is, representing the nodes of a dynamic network as evolving vectors within a low-dimensional space. While the field of static network embedding is wide and established, the field of dynamic network embedding is comparatively in its infancy. We propose that a wide class of established static network embedding methods can be used to produce interpretable and powerful dynamic network embeddings when they are applied to the dilated unfolded adjacency matrix. We provide a theoretical guarantee that, regardless of embedding dimension, these unfolded methods will produce stable embeddings, meaning that nodes with identical latent behaviour will be exchangeable, regardless of their position in time or space. We additionally define a hypothesis testing framework which can be used to evaluate the quality of a dynamic network embedding by testing for planted structure in simulated networks. Using this, we demonstrate that, even in trivial cases, unstable methods are often either conservative or encode incorrect structure. In contrast, we demonstrate that our suite of stable unfolded methods are not only more interpretable but also more powerful in comparison to their unstable counterparts.